Przykładowy przepływ pracy deep learning wykorzystujący TensorFlow uruchomiony w środowisku Docker na maszynie wirtualnej NSIS vGPU
W tym artykule przedstawiono wykorzystanie narzędzi deep learningu TensorFlow i Keras do wykonywania niestandardowej klasyfikacji obrazów na vGPU w .
Wykorzystanie (v)GPU przyspieszy obliczenia związane z deep learningiem. W tym przykładzie skróci to czas przetwarzania z kilku godzin do kilku minut.
Zadanie, do którego zastosujesz TensorFlow, polega na rozpoznaniu, które zestawy obrazów są przycięte, a które nie. W dwóch zestawach obrazów pokazanych poniżej, obrazy po lewej stronie nie są przycięte, a te po prawej są. Model, który opracujesz w tym artykule, będzie w stanie wyciągnąć (mniej więcej) takie same wnioski, jak ludzie dla tego samego zestawu zdjęć.

Ostrzeżenie
Przetwarzanie obrazów satelitarnych to odrębna dyscyplina wykorzystująca różne techniki. Ten artykuł koncentruje się na absolutnych podstawach, aby zademonstrować koncepcję i możliwy przepływ pracy podczas korzystania z deep learningu na maszynie vGPU.
Opracowany tutaj model jest tylko przykładem. Wykorzystanie go w produkcji wymagałoby dalszych testów. Model nie jest deterministyczny i przy każdym treningu będzie dawał inne wyniki.
Jeśli chcesz wykonać ten przepływ prac deep learningu bez użycia Dockera, zapoznaj się z artykułami: Instalacja TensorFlow na maszynie wirtualnej z włączoną obsługą vGPU na NSIS Cloud oraz Przykładowy przepływ pracy deep learning przy użyciu vGPU i EO-DATA na NSIS.
Co zamierzamy zrobić?
Wyjaśnić szczegółowo kod w języku Python używany w tym procesie.
Użyć Dockera jako środowiska do tworzenia modeli
Utworzyć obraz kontenera o nazwie deeplearning w oparciu o publiczny obraz tensorflow/tensorflow:2.11.0-gpu.
Pobrać dane do testowania i treningu
Zainstalować nasz skrypt w języku Python deeplearning.py w kontenerze środowiska Docker
Zainstalować zależności wymagane przez aplikację (pandas i numpy).
Uruchomić model w oparciu o dane pobrane z tego artykułu.
Przeanalizować wyniki
Wykonać testy porównawcze modelu na wariantach (flavor) vm.a6000.1 i vm.a6000.8 i wykazać, że na drugim z nich proces jest nawet pięć razy szybszy
Wymagania wstępne
Nr 1 Konto
Jest wymagane konto hostingowe NSIS z dostępem do interfejsu Horizon: https://horizon.cloudferro.com.
Nr 2 Utworzenie nowej maszyny wirtualnej z systemem Linux z wirtualnym procesorem graficznym NVIDIA
Tworzenie nowej maszyny wirtualnej z systemem Linux z vGPU opisuje artykuł: Jak utworzyć nową maszynę wirtualną Linux z NVIDIA Virtual GPU w Dashboardzie OpenStack Horizon na NSIS Cloud.
Nr 3 Dodanie Floating IP do maszyny wirtualnej
Jak dodać lub usunąć Floating IP maszyny wirtualnej w NSIS.
Teraz będzie można używać tego floating IP w przykładach opisanych w niniejszym artykule.
Nr 4 TensorFlow zainstalowany w środowisku Docker
TensorFlow należy zainstalować za pomocą Dockera na maszynie wirtualnej NSIS obsługującej GPU. Poniższy artykuł opisuje, jak można to zrobić: /cuttingedge/Install-TensorFlow-on-Docker-Running-on-NSIS-vGPU-Virtual-Machine/.
Nr 5 Uruchomienie lokalnie na komputerze z systemem Ubuntu 20.04 LTS.
W tym artykule założono, że na lokalnym komputerze jest zainstalowany system Ubuntu 20.04 LTS. Można jednak uruchomić ten model z dowolnego innego systemu operacyjnego, pod warunkiem że będą używane odpowiednie polecenia umożliwiające operacje na plikach, dostęp SSH itp.
Objaśnienie kodu
Ta sekcja zawiera szczegółowe wyjaśnienie tego procesu i wykorzystywanego w nim kodzie w języku Python. Aby zapoznać się z praktycznymi krokami umożliwiającymi odtworzenie tego procesu, należy rozpocząć od sekcji Praktyczny przepływ pracy (patrz poniżej). Nie będzie konieczne samodzielne kopiowanie kodu w języku Python, zawierający go plik jest dostępny do pobrania.
Krok 1: Przygotowanie danych
Przygotowanie danych jest podstawowym (i zwykle najbardziej czasochłonnym) krokiem w każdym projekcie związanym z Data Science. Aby nasz model deep learning mógł się uczyć, będziemy postępować zgodnie z typową sekwencją czynności (uczenie nadzorowane):
Przygotuj wystarczająco dużą próbkę danych (w rym przykładzie jest to próbka zdjęć satelitarnych Sentinel-2).
Oznacz i otaguj te dane ręcznie (tę czynność wykonuje człowiek). W naszym przykładzie ręcznie rozdzieliliśmy obrazy na kategorie „edges” i „noedges”, reprezentujące odpowiednio obrazy przycięte i nieprzycięte.
Wydziel część tych danych jako podzbiór Train(+Validation), który zostanie użyty do uczenia modelu.
Wydziel kolejny podzbiór Test. Jest to podzbiór kontrolny, którego model nigdy nie widzi podczas fazy uczenia się, będzie on używany do oceny jakości modelu.
Plik .zip do pobrania znajdujący się w dalszej części tego artykułu jest zawiera już gotowy zestaw danych (zgodny z tymi krokami). Zawiera on:
592 pliki zestawu Train/Validate (po połowie obrazów przyciętych/nieprzyciętych)
148 plików zestawu testowego (również po połowie obrazów przyciętych/nieprzyciętych).
Na podstawie nazw katalogów i podkatalogów z tego zbioru danych Keras automatycznie przypisze etykiety, więc ważne jest, aby zachować strukturę folderów bez zmian.
Ostatnim krokiem jest wykonanie niezbędnych operacji na danych, tak aby stanowiły one odpowiednie dane wejściowe dla modelu. TensorFlow wykona dużą część tej pracy za nas. Przykładowo, za pomocą funkcji image_dataset_from_directory, każdy obraz jest automatycznie etykietowany i konwertowany na wektory/macierz liczb: wysokość x szerokość x głębokość (warstwa RGB).
W tym konkretnym przypadku użycia może być konieczne wykonanie na tym etapie różnych optymalizacji danych.
import numpy as np
import tensorflow as tf
from tensorflow import keras
import pandas as pd
# DATA INGESTION
# -------------------------------------------------------------------------------------
# Ingest the Training, Validation and Test datasets from image folders.
# The labels (edges vs. noedges) are automatically inferred based on folder names.
train_ds = keras.utils.image_dataset_from_directory(
directory='./data/train',
labels='inferred',
label_mode='categorical',
validation_split=0.2,
subset='training',
image_size=(343, 343),
seed=123,
batch_size=8)
val_ds = keras.utils.image_dataset_from_directory(
directory='./data/train',
labels='inferred',
label_mode='categorical',
validation_split=0.2,
subset='validation',
image_size=(343, 343),
seed=123,
batch_size=8)
test_ds = keras.utils.image_dataset_from_directory(
directory='./data/test',
labels='inferred',
label_mode='categorical',
image_size=(343, 343),
shuffle = False,
batch_size=1)
Krok 2: Definiowanie i szkolenie modelu
Definiowanie optymalnego modelu jest sztuką i nauką Data Science. To, co tutaj pokazujemy, to tylko prosty przykładowy model i należy przeczytać więcej z innych źródeł na temat tworzenia modeli dla rzeczywistych scenariuszy.
Po zdefiniowaniu modelu jest on kompilowany i rozpoczyna się jego szkolenie. Każda epoka to kolejna iteracja dostrajania modelu. Te epoki są złożonymi i intensywnymi operacjami obliczeniowymi. Korzystanie z vGPU ma fundamentalne znaczenie dla aplikacji deep learning, ponieważ umożliwia rozdzielenie mikrozadań na setki rdzeni, co znacznie przyspiesza proces.
Po dostosowaniu modelu zapiszemy go i ponownie wykorzystamy do generowania prognoz.
# TRAINING
# -------------------------------------------------------------------------------------
# Build, compile and fit the Deep Learning model
model = keras.applications.Xception(
weights=None, input_shape=(343, 343, 3), classes=2)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics='accuracy')
model.fit(train_ds, epochs=5, validation_data=val_ds)
model.save('model_save.h5')
# to reuse the model later:
#model = keras.models.load_model('model_save.h5')
Krok 3: Generowanie prognoz dla danych testowych
Po wytrenowaniu modelu generowanie prognoz jest prostą i znacznie szybszą operacją. Jak wspomniano wcześniej, użyjemy modelu do wygenerowania prognoz dla danych testowych.
# GENERATE PREDICTIONS on previously unseen data
# -------------------------------------------------------------------------------------
predictions_raw = model.predict(test_ds)
Krok 4: Podsumowanie wyników
W tym kroku bierzemy rzeczywiste etykiety („edges” i „noedges”, które reprezentują odpowiednio obrazy „przycięte” i „nieprzycięte”) i porównujemy je z etykietami, które przewidział nasz model.
Podsumowujemy wyniki w ramce danych zapisanej jako plik CSV, co umożliwia interpretację rzeczywistych wyników w zestawie testowym w porównaniu z przewidywaniami dostarczonymi przez model.
Przykład danych wyjściowych w formacie CSV:
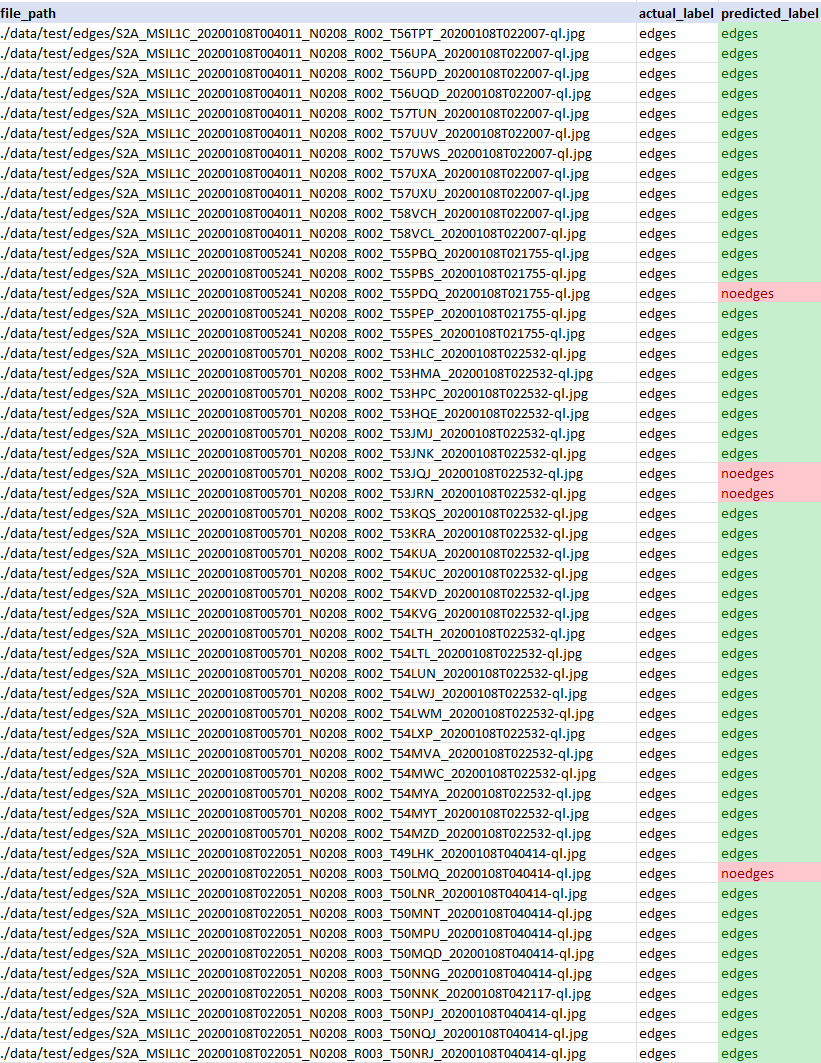
# SUMMARIZE RESULTS (convenience, alternative approaches are available)
# -------------------------------------------------------------------------------------
# initialize pandas dataframe with file paths
df = pd.DataFrame(data = {"file_path": test_ds.file_paths})
class_names = test_ds.class_names # ["edges","noedges"]
# add actual labels column
def get_actual_label(label_vector):
for index, value in enumerate(label_vector):
if (value == 1):
return class_names[index]
actual_label_vectors = np.concatenate([label for data, label in test_ds], axis=0).tolist() # returns array of label vectors [[0,1],[1,0],...] representing category (edges/noedges)
actual_labels = list(map(lambda alv: get_actual_label(alv), actual_label_vectors))
df["actual_label"] = actual_labels
# add predicted labels column
predictions_binary = np.argmax(predictions_raw, axis=1) # flatten to 0-1 recommendation
predictions_labeled = list(map(lambda x: class_names[0] if x == 0 else class_names[1],list(predictions_binary)))
df["predicted_label"] = predictions_labeled
df.to_csv("results.csv", index=False)
Praktyczny przepływ pracy
Ta sekcja opisuje praktyczne kroki, które umożliwiają samodzielne wykonanie tego przepływu pracy. Jest to tylko przykład i można samodzielnie utworzyć inny przepływ pracy.
Przed wykonaniem poniższych czynności praktycznych zapoznaj się ponownie z sekcją Wymagania wstępne.
Wymagane pliki można przesłać na maszynę wirtualną przy użyciu różnych metod, takich jak:
- Pobranie plików na komputer lokalny i skopiowanie ich za pomocą programu scp na maszynę wirtualną.
Kliknij poniższe linki, aby pobrać dane
- Pobierz pliki bezpośrednio na maszynę wirtualną za pomocą programu wget.
Metoda ta zostanie opisana w Kroku 1.
Krok 1: Pobranie zasobów na maszynę wirtualną
Połącz się z maszyną wirtualną za pomocą SSH (zastąp 64.225.129.70 Floating IP maszyny wirtualnej).
ssh eouser@64.225.129.70
Informacja
Pomiń resztę tego kroku, jeśli skopiowane pliki zostały już przeniesione na maszynę wirtualną przy użyciu innej metody.
Pobierz wymagane zasoby na maszynę wirtualną za pomocą poniższego polecenia:
wget https://creodias.docs.cloudferro.com/en/latest/_downloads/3ec8990b08af7d4478a6820abb172705/data.zip https://creodias.docs.cloudferro.com/en/latest/_downloads/1c3a17567b2f4f1ff87ddbbfe005db42/deeplearning.py
Wykonaj polecenie ls, aby sprawdzić, czy skopiowane pliki się tam znajdują:

Krok 2: Przeniesienie pobranych zasobów do odpowiedniej lokalizacji
Utwórz katalog o nazwie deeplearning na maszynie wirtualnej, w którym umieścisz pobrane zasoby:
mkdir deeplearning
Użyj poniższego polecenia, aby przenieść wymagane pliki do tego katalogu:
mv deeplearning.py data.zip deeplearning
Teraz przejdź do utworzonego przed chwilą katalogu:
cd deeplearning
Krok 3: Utworzenie pliku Dockerfile i pliku requirements.txt
Zainstaluj edytor tekstowy nano, jeśli jeszcze nie jest zainstalowany i utwórz za jego pomocą plik Dockerfile w bieżącym katalogu roboczym (plik tekstowy o nazwie Dockerfile):
sudo apt install nano
nano Dockerfile
Wklej do niego następujący kod:
# syntax=docker/dockerfile:1
FROM tensorflow/tensorflow:2.11.0-gpu
WORKDIR /app
RUN mkdir data
COPY deeplearning.py .
COPY data ./data
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
Po wklejeniu ekran powinien wyglądać następująco:
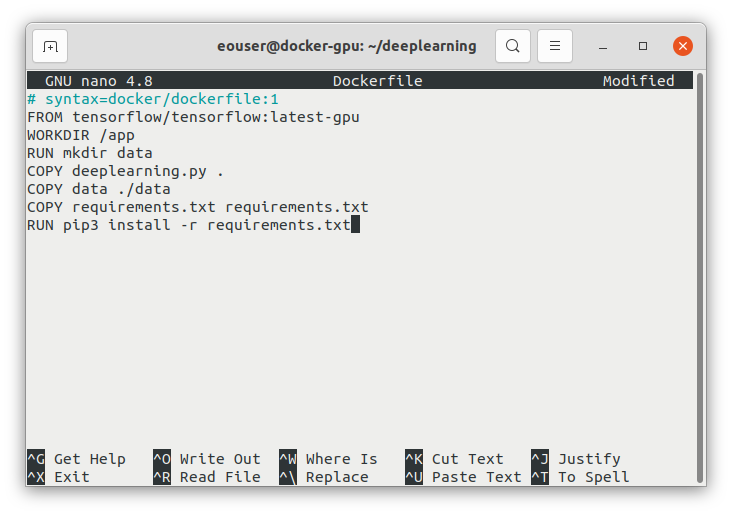
Zapisz plik i wyjdź z nano, używając następującej sekwencji klawiszy: naciśnij CTRL+X, potem Y, a następnie Enter.
Dodaj plik tekstowy requirements.txt w tym samym katalogu przy użyciu tej samej metody:
nano requirements.txt
Wpisz w edytorze następujący tekst:
numpy==1.22.4
pandas==1.4.2
Użycie pliku requirements.txt jest standardowym sposobem na skonfigurowanie i zainstalowanie potrzebnych rozszerzeń w środowisku Python.
Zapisz plik i wyjdź z nano w taki sam sposób jak poprzednio: CTRL+X, Y, Enter.
Krok 4: Rozpakowanie i usunięcie archiwum zawierającego dane treningowe
Rozpakuj archiwum data.zip, a następnie usuń je:
unzip data.zip
rm data.zip
Krok 5: Sprawdzenie, czy wszystkie potrzebne pliki znajdują się we właściwym miejscu
Wykonaj polecenie ls, aby sprawdzić, czy znajdują się tam następujące pliki:
katalog data
plik deeplearning.py.
plik Dockerfile
plik requirements.txt

Krok 6: Utworzenie obrazu Docker i wejście do niego
Z katalogu z plikiem Dockerfile uruchom następujące polecenie, aby utworzyć obraz kontenera:
sudo docker build -t deeplearning .
Następnie uruchom kontener za pomocą powłoki interaktywnej:
sudo docker run -it --gpus all -v /tmp/:/tmp/ deeplearning /bin/bash
Powinien zostać wyświetlony następujący ekran:
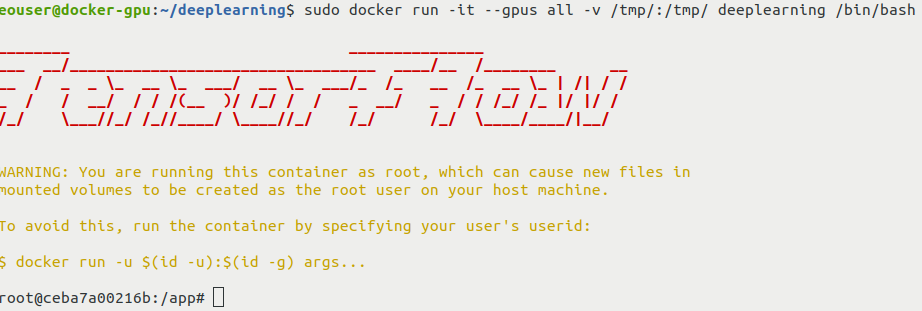
Opcja -v spowoduje zamontowanie współdzielonego volume pomiędzy kontenerem a maszyną wirtualną hosta. Umożliwi to kopiowanie plików wygenerowanych przez nasz skrypt na maszynę wirtualną hosta.
Krok 7: Uruchomienie kodu w języku Python
Z kontenera uruchom skrypt w języku Python:
python3 deeplearning.py
Na maszynie wirtualnej obsługującej vGPU wykonanie tego skryptu powinno trwać kilka minut. W wyniku tej operacji powinien zostać utworzony plik results.csv zawierający wyniki. Ponadto, aby uniknąć powtarzania treningu, model jest zapisywany jako plik o nazwie model_save.h5.
Krok 8: Wyodrębnienie plików z kontenera
Po zakończeniu, ostatnim krokiem jest skopiowanie plików z katalogu /tmp w kontenerze do katalogu /tmp na komputerze hosta. Wykonaj z interaktywnej powłoki kontenera następujące polecenie:
cp results.csv model_save.h5 /tmp
Możesz teraz opuścić kontener za pomocą następującego polecenia:
exit
Po opuszczeniu kontenera przejdź do katalogu /tmp na maszynie wirtualnej:
cd /tmp
Użyj polecenia ls, aby sprawdzić, czy znajdują się tam pliki results.csv i model_save.h5 zawierające wyniki tej operacji. W następnym kroku skopiujemy je na komputer lokalny.
Teraz można również odłączyć się od maszyny wirtualnej:
exit
Krok 9: Pobranie pliku z wynikami na komputer lokalny
Teraz należy pobrać wyniki i zapisany model na komputer lokalny. Ustaw katalog zawierający plik results.csv jako bieżący katalog roboczy, a następnie wykonaj następujące polecenie (zastąp 64.225.129.70 floating IP swojej maszyny wirtualnej):
scp eouser@64.225.129.70:/tmp/results.csv eouser@64.225.129.70:/tmp/model_save.h5 .
Plik csv zawierający wyniki i plik zawierający model powinny teraz znajdować się na komputerze lokalnym:

Porównanie wydajności
Ten artykuł zakłada, że TensorFlow jest zainstalowany w środowisku Docker. Istnieje równoległy artykuł z tym samym przykładem uruchamianym bezpośrednio w chmurze WAW3-1 (Przykładowy przepływ pracy deep learning przy użyciu vGPU i EO-DATA na NSIS). Teraz zamierzamy porównać czasy działania dla tych obu środowisk, używając najmniejszych i największych flavorów dla vGPU, vm.a6000.1 i vm.a6000.8.
Poniższa tabela zawiera czas potrzebny do zakończenia wykonywania kodu w języku Python. Został on zmierzony przy użyciu polecenia time („wartość rzeczywista”). Wszystkie testy zostały przeprowadzone w chmurze NSIS.
+---------------------+-------------+-----------------+
| | vm.a6000.1 | vm.a6000.8 |
| Docker used | 5m50.449s | 1m14.446s |
| Docker not not used | 5m0.276s | 0m55.547s |
Cały proces zajął około 5 razy mniej czasu na wersji instancji (flavor) vm.a6000.8 niż na wersji vm.a6000.1. W przypadku korzystania z Dockera wydajność zmniejsza się nieznacznie, ale jest to spodziewane.
Informacja
Ten test porównawczy uwzględnia wszystkie fazy wykonywania kodu w języku Python i nie wszystkie z nich mogą w takim samym stopniu wykorzystywać lepszy sprzęt.
Co można dalej zrobić
Ten przepływ pracy można również wykonać bez użycia Dockera. Jeśli chcesz to zrobić, zapoznaj się z poniższym artykułem:
Przykładowy przepływ pracy deep learning przy użyciu vGPU i EO-DATA na NSIS.
Ostrzeżenie
Przykłady w tym artykule mogą być niereprezentatywne, a ich przebieg może się różnić. Użyj tego kodu i całego artykułu jako punktu wyjścia do przeprowadzenia własnych badań.