Automatyczne skalowanie zasobów klastra Kubernetes na platformie NSIS OpenStack Magnum
Gdy automatyczne skalowanie klastrów Kubernetes jest włączone, system może:
dodawać zasoby, gdy zapotrzebowanie jest wysokie, lub
usuwać niepotrzebne zasoby, gdy zapotrzebowanie jest niskie, a tym samym obniżyć koszty.
Cały proces może być zautomatyzowany, co pomaga administratorowi skupić się na ważniejszych zadaniach.
Ten artykuł wyjaśnia różne polecenia służące do zmiany rozmiaru lub skalowania klastra i opisuje również polecenie automatycznego tworzenia autoskalowalnego klastra Kubernetes dla OpenStack Magnum.
Co zostanie omówione?
Definicje skalowania poziomego, pionowego i skalowania węzłów
Definiowanie automatycznego skalowania podczas tworzenia klastra w interfejsie Horizon
Definiowanie automatycznego skalowania podczas tworzenia klastra za pomocą CLI
Pobieranie etykiet szablonów klastrów z interfejsu Horizon
Pobieranie etykiet szablonów klastrów z interfejsu CLI
Wymagania wstępne
Nr 1 Hosting
Wymagane jest konto hostingowe NSIS z interfejsem Horizon https://horizon.cloudferro.com.
Nr 2 Utworzenie klastrów za pomocą CLI
Artykuł Jak korzystać z interfejsu wiersza poleceń dla klastrów Kubernetes w NSIS OpenStack Magnum wprowadzi cię w zagadnienia tworzenia klastrów za pomocą interfejsu wiersza poleceń.
Nr 3 Podłączenie klienta openstack do chmury
Przygotuj klienty openstack i magnum, wykonując Krok 2 Podłączanie klientów OpenStack i Magnum do chmury Horizon z artykułu Jak zainstalować klientów OpenStack i Magnum dla interfejsu wiersza poleceń w NSIS Horizon?.
Nr 4. Zmiana rozmiaru nodegroups
Krok 7 artykułu Tworzenie dodatkowych nodegroups w klastrze Kubernetes na platformie NSIS OpenStack Magnum pokazuje przykład zmiany rozmiaru nodegroups dla automatycznego skalowania.
Nr 5 Utworzenie klastrów
Krok 2 artykułu Jak utworzyć klaster Kubernetes przy użyciu NSIS OpenStack Magnum pokazuje, jak zdefiniować węzły główne i robocze dla automatycznego skalowania.
Chmura Kubernetes może oferować trzy różne funkcje automatycznego skalowania:
Poziomy autoskaler podów
Skalowanie klastra Kubernetes w poziomie oznacza zwiększanie lub zmniejszanie liczby uruchomionych podów w zależności od rzeczywistych wymagań w czasie wykonywania. Parametry, które należy wziąć pod uwagę, to wykorzystanie procesora i pamięci, a także pożądana minimalna i maksymalna liczba replik podów.
Skalowanie poziome jest również znane jako „scaling out”, jest również używany skrót HPA.
Pionowy autoskaler podów
Skalowanie pionowe (lub „skalowanie w górę”, VPA) polega na dodawaniu lub odejmowaniu zasobów do i od istniejącej maszyny. Jeśli potrzeba więcej procesorów, należy je dodać. Gdy nie są one potrzebne, wyłącz niektóre z nich.
Autoskaler klastrów
HPA i VPA reorganizują wykorzystanie zasobów i liczbę podów, jednak może się zdarzyć, że rozmiar samego systemu uniemożliwi zaspokojenie zapotrzebowania. Rozwiązaniem jest autoskalowanie samego klastra, aby zwiększyć lub zmniejszyć liczbę węzłów, na których będą działać pody.
Po dostosowaniu liczby węzłów, pody i inne zasoby muszą ponownie zostać zrównoważone w klastrze, również automatycznie. Liczba węzłów stanowi fizyczną granicę dla automatycznego skalowania podów.
Wszystkie trzy modele automatycznego skalowania można ze sobą łączyć.
Definiowanie Autoscalingu podczas tworzenia clustra
Parametry automatycznego skalowania można określić podczas definiowania nowego klastra, korzystając z okna Size w kreatorze tworzenia klastra:
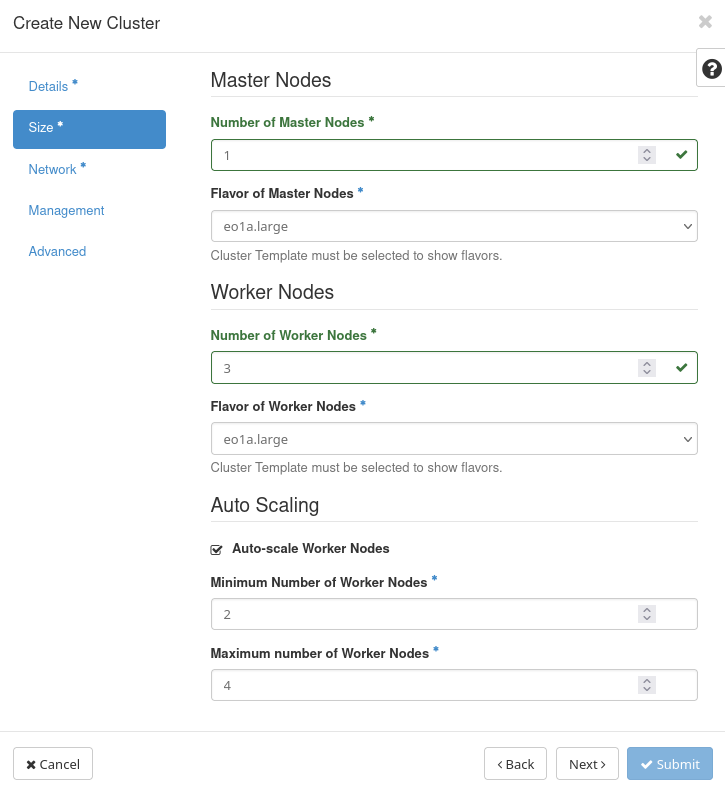
Określa minimalną i maksymalną liczbę węzłów roboczych. Jeśli te wartości wynoszą odpowiednio 2 i 4, klaster będzie miał w każdym momencie nie mniej niż 2 węzły i nie więcej niż 4 węzły. Jeśli nie ma ruchu do klastra, zostanie on automatycznie skalowany do 2 węzłów. W tym przykładzie klaster może mieć 2, 3 lub 4 węzły w zależności od natężenia ruchu.
Ostrzeżenie
Jeśli podczas definiowania klastra zdecydujesz się użyć opcji NGINX Ingress, NGINX ingress będzie działać jako 3 repliki na 3 oddzielnych węzłach. Spowoduje to zastąpienie minimalnej liczby węzłów w autoskalerze Magnum.
Automatyczne skalowanie grup węzłów podczas pracy
Autoskaler w Magnum wykorzystuje grupy węzłów. Grupy węzłów mogą być używane do tworzenia węzłów roboczych z różnymi flavorami. Domyślna grupa węzłów roboczych jest tworzona automatycznie podczas tworzenia klastra. Grupy węzłów mają dolne i górne limity liczby węzłów. Polecenie umożliwiające wyświetlenie parametrów dla danego klastra jest następujące:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c max_node_count -c node_count -c min_node_count
Wynik wyglądałby następująco:
{
"node_count": 1,
"max_node_count": 2,
"min_node_count": 1
}
Działa to dobrze, dopóki nie spróbujesz zmienić rozmiaru klastra poza limit ustawiony w grupie węzłów. Jeśli spróbujesz zmienić rozmiar powyższego klastra na 12 węzłów, tak jak poniżej:
openstack coe cluster resize NoLoadBalancer --nodegroup default-worker 12
zostanie zwrócony następujący błąd:
Resizing default-worker outside the allowed range: min_node_count = 1, max_node_count = 2 (HTTP 400) (Request-ID: req-bbb09fc3-7df4-45c3-8b9b-fbf78d202ffd)
Aby usunąć ten błąd, należy ręcznie zmienić wartość parametru node_group max_node_count:
openstack coe nodegroup update NoLoadBalancer default-worker replace max_node_count=15
a następnie zmienić rozmiar klastra do żądanej wartości, która w tym przykładzie była mniejsza niż 15:
openstack coe cluster resize NoLoadBalancer –nodegroup default-worker 12
Jeśli powtórzysz pierwsze polecenie:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c max_node_count -c node_count -c min_node_count
wynik będzie miał teraz poprawioną wartość:
{
"node_count": 12,
"max_node_count": 15,
"min_node_count": 1
}
Jak automatyczne skalowanie wykrywa górny limit
Pierwsza wersja automatycznego skalowania przyjmie aktualną górną granicę określoną w zmiennej node_count i doda do niego 1. Jeśli polecenie utworzenia klastra brzmiałoby:
openstack coe cluster create mycluster --cluster-template mytemplate --node-count 8 --master-count 3
ta wersja autoskalera przyjmie wartość 9 (liczoną jako 8 + 1). Procedura ta jest jednak ograniczona tylko do domyślnej grupy węzłów roboczych.
Obecny autoskaler może obsługiwać wiele grup węzłów poprzez wykrywanie roli grupy węzłów:
openstack coe nodegroup show NoLoadBalancer default-worker -f json -c role
Wynik jest następujący:
{
"role": "worker"
}
Dopóki rolą jest worker, a wartość max_node_count jest większa niż 0, autoskaler będzie próbował skalować grupę węzłów default-worker dodając 1 do max_node_count.
Uwaga
Każda dodatkowa grupa węzłów musi zawierać konkretny atrybut max_node_count.
Szczegółowe przykłady korzystania z grupy poleceń openstack coe nodegroup można znaleźć w sekcji Wymaganie wstępne nr4.
Automatyczne skalowanie etykiet dla klastrów
Istnieją trzy etykiety dla klastrów, które wpływają na automatyczne skalowanie:
auto_scaling_enabled – jeśli wartość to true, funkcja jest włączona
min_node_count – minimalna liczba węzłów
max_node_count – the maximal number of nodes, at any time.
Podczas definiowania klastra za pośrednictwem interfejsu Horizon, użytkownik faktycznie konfiguruje te etykiety klastra.
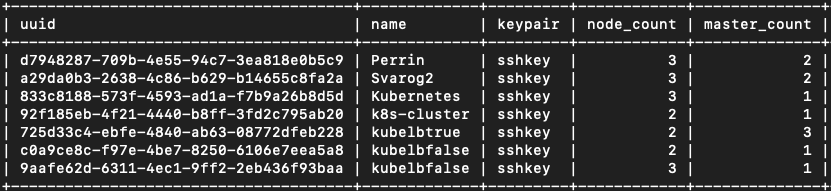
Wyświetl listę klastrów za pomocą Container Infra => Cluster i kliknij nazwę klastra. W sekcji Labels znajdziesz aktualną wartość dla auto_scaling_enabled.

Jeśli jest ustawiona wartość true, klaster będzie skalowany automatycznie.
Tworzenie nowego klastra przy użyciu interfejsu CLI z włączonym automatycznym skalowaniem.
Polecenie utworzenia klastra za pomocą CLI musi zawierać wszystkie zwykłe parametry, a także wszystkie etykiety potrzebne do działania klastra. Specyfika składni polega na tym, że parametry etykiet muszą być pojedynczym ciągiem znaków, bez spacji pomiędzy nimi.
Jedno z takich poleceń mogłoby wyglądać tak:
openstack coe cluster create mycluster
--cluster-template k8s-stable-1.23.5
--keypair sshkey
--master-count 1
--node-count 3
--labels auto_scaling_enabled=true,autoscaler_tag=v1.22.0,calico_ipv4pool_ipip=Always,cinder_csi_plugin_tag=v1.21.0,cloud_provider_enabled=true,cloud_provider_tag=v1.21.0,container_infra_prefix=registry-public.cloudferro.com/magnum/,eodata_access_enabled=false,etcd_volume_size=8,etcd_volume_type=ssd,hyperkube_prefix=registry-public.cloudferro.com/magnum/,k8s_keystone_auth_tag=v1.21.0,kube_tag=v1.21.5-rancher1,master_lb_floating_ip_enabled=true
Jeśli po prostu spróbujesz skopiować je i wkleić go do terminala, otrzymasz błędy składni. Końce wiersza są niedozwolone, całe polecenie musi być jednym długim ciągiem. Aby ułatwić ci pracę, oto wersja polecenia, którą możesz skopiować.
Ostrzeżenie
Wiersz zawierający etykiety będzie tylko częściowo widoczna na ekranie, ale po wklejeniu go do wiersza poleceń oprogramowanie terminala wykona ją bez problemów.
Polecenie jest następujące:
openstack coe cluster create mycluster –cluster-template k8s-stable-1.23.5 –keypair sshkey –master-count 1 –node-count 3 –labels auto_scaling_enabled=true,autoscaler_tag=v1.22.0,calico_ipv4pool_ipip=Always,cinder_csi_plugin_tag=v1.21.0/,cloud_provider_enabled=true,cloud_provider_tag=v1.21.0,container_infra_prefix=registry-public.cloudferro.com/magnum/,eodata_access_enabled=false,etcd_volume_size=8,etcd_volume_type=ssd,hyperkube_prefix=registry-public.cloudferro.com/magnum/,k8s_keystone_auth_tag=v1.21.0,kube_tag=v1.21.5-rancher1,master_lb_floating_ip_enabled=true,min_node_count=2,max_node_count=4
Nazwa będzie brzmiała mycluster, a jeden węzeł główny i trzy węzły robocze znajdują się na początku.
Informacja
Ustawienie maksymalnej liczby węzłów dla automatycznego skalowania jest obowiązkowe. Jeśli ich liczba nie zostanie określona, wartość max_node_count będzie domyślnie wynosić 0 i żadne automatyczne skalowanie nie będzie przeprowadzane dla danej grupy węzłów.
Po utworzeniu wynik jest następujący:
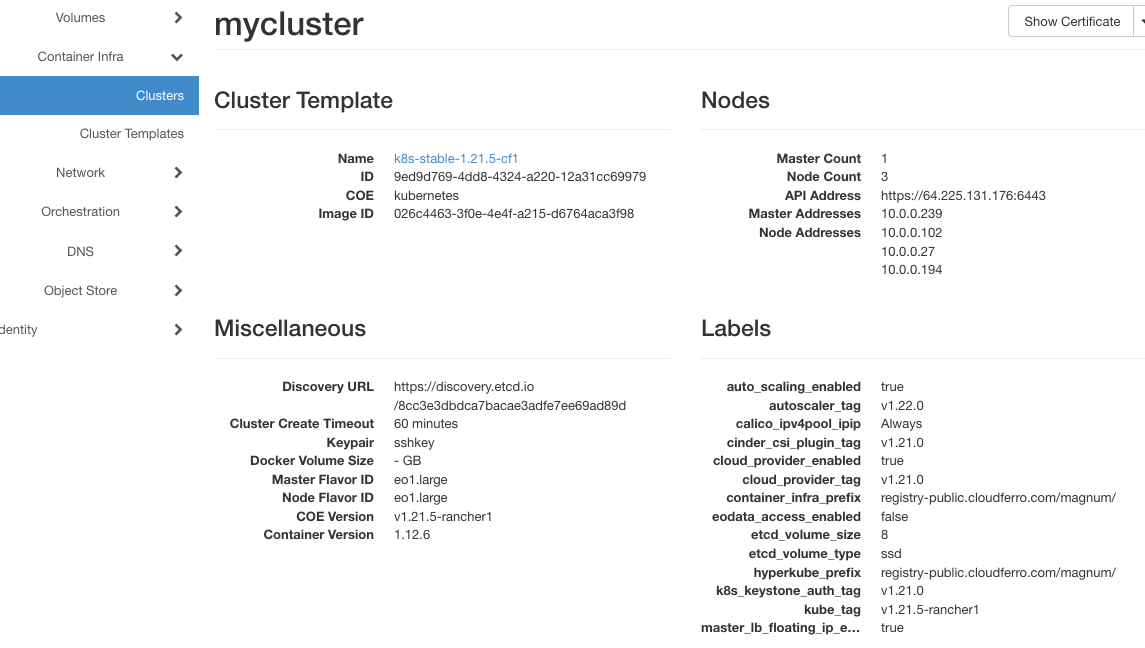
Aktywne są trzy adresy węzłów roboczych: 10.0.0.102, 10.0.0.27 i 10.0.0.194.
Ponieważ nie ma ruchu do klastra, automatyczne skalowanie uruchomiło się natychmiast. Minutę lub dwie po zakończeniu tworzenia klastra liczba węzłów roboczych spadła o jeden, do adresów 10.0.0.27 i 10.0.0.194 - podczas pracy działa automatyczne skalowanie.
Nodegroups z rolą węzła roboczego będą skalowane automatycznie
Autoscaler automatycznie wykrywa wszystkie nowe grupy węzłów z przypisaną rolą »worker«. Rola »worker« jest przypisywana domyślnie, jeśli nie zostanie określona. Należy również określić maksymalną liczbę węzłów.
Najpierw sprawdź, które nodegroups są obecne dla klastra k8s-cluster. Polecenie jest następujące:
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
Przełącznik -c oznacza, która kolumna ma zostać wyświetlona. Wszystkie inne kolumny, które nie są wymienione w poleceniu zostaną pominięte. Zobaczysz tabelę z kolumnami name, node_count, status i role, co oznacza, że kolumny takie jak uuid, flavor_id i image_id nie będą zajmować cennego miejsca na ekranie. Rezultatem jest tabela zawierająca tylko cztery kolumny, które są istotne dla dodawania grup węzłów z rolami:

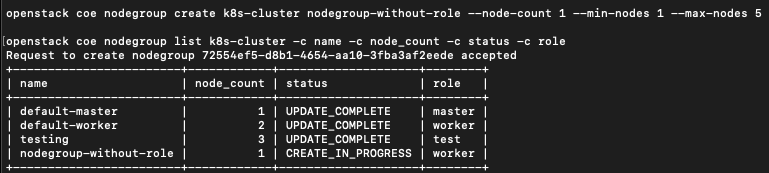
Teraz dodaj i wyświetl grupę węzłów bez roli:
openstack coe nodegroup create k8s-cluster nodegroup-without-role --node-count 1 --min-nodes 1 --max-nodes 5
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
Ponieważ rola nie została określona, do nodegroup nodegroup-without-role została przypisana domyślna wartość „worker” . Ponieważ system jest skonfigurowany do automatycznego skalowania nodegroups z rolą worker, jeśli dodasz nodegroup bez roli, będzie ona automatycznie skalowana.
Teraz dodaj grupę węzłów o nazwie nodegroup-with-role, nazwą roli będzie custom:
openstack coe nodegroup create k8s-cluster nodegroup-with-role --node-count 1 --min-nodes 1 --max-nodes 5 --role custom
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
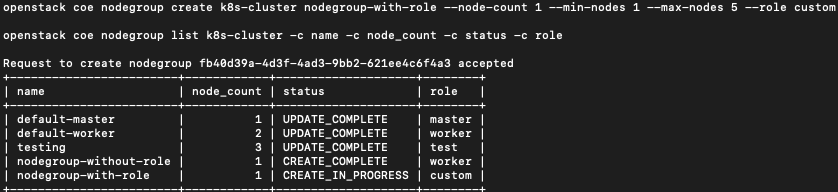
Spowoduje to dodanie grupy węzłów, ale nie włączy jej automatycznego skalowania, ponieważ dla grupy węzłów nie określono roli worker.
Na koniec dodaj nodegroup o nazwie nodegroup-with-role-2, która będzie miała dwie role zdefiniowane w jednej instrukcji, czyli zarówno custom, jak i worker. Ponieważ co najmniej jedną z ról jest worker, będzie ona automatycznie skalowana.
openstack coe nodegroup create k8s-cluster nodegroup-with-role-2 --node-count 1 --min-nodes 1 --max-nodes 5 --role custom,worker
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
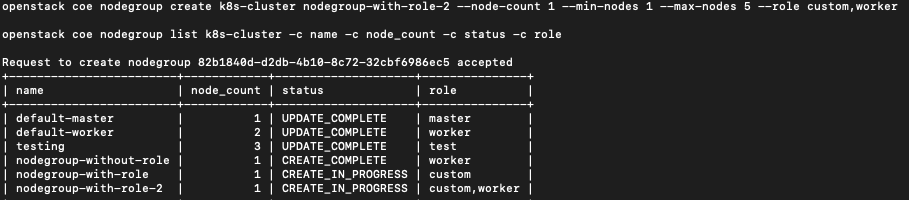
Klaster k8s-cluster ma teraz 8 węzłów:
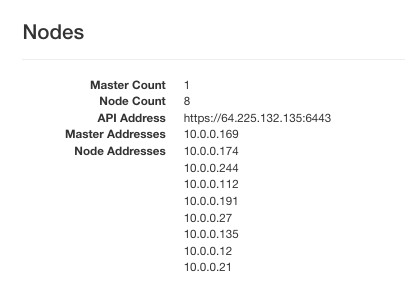
Te trzy klastry można usunąć za pomocą następującego zestawu poleceń:
openstack coe nodegroup delete k8s-cluster nodegroup-with-role
openstack coe nodegroup delete k8s-cluster nodegroup-with-role-2
openstack coe nodegroup delete k8s-cluster nodegroup-without-role
Zobacz jeszcze raz wynik:
openstack coe nodegroup list k8s-cluster -c name -c node_count -c status -c role
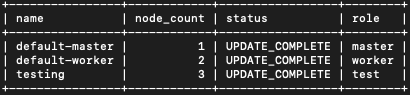
Jak uzyskać wszystkie etykiety z interfejsu Horizon
W sekcji Container Infra => Clusters i kliknij nazwę klastra. W przeglądarce pojawi się zwykły tekst, wystarczy skopiować wiersze z sekcji Labels i wkleić je do wybranego edytora tekstu.
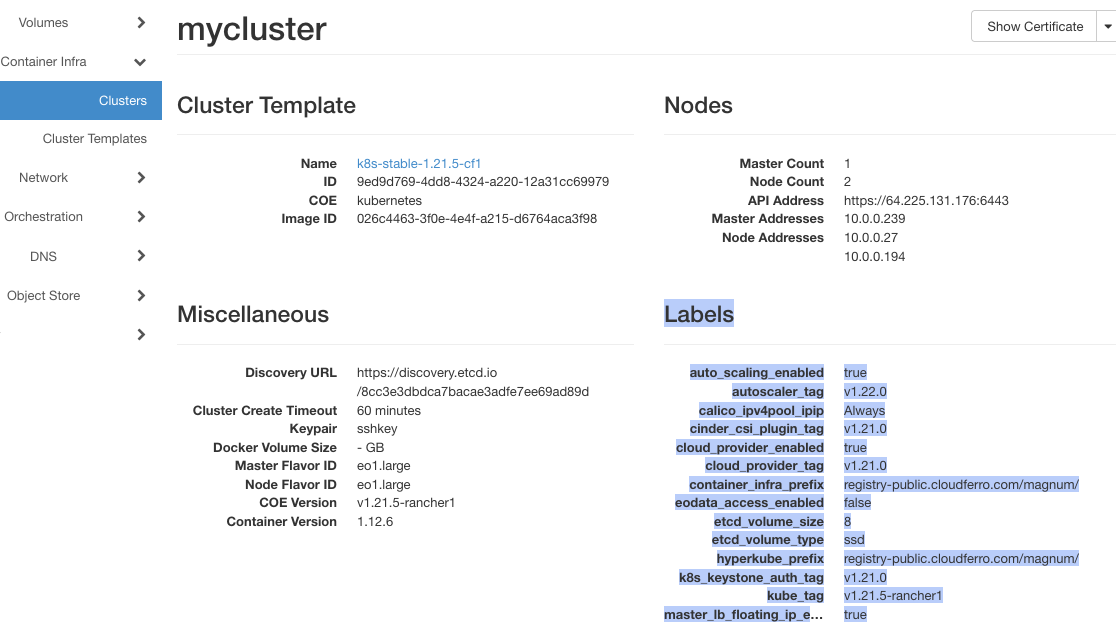
W edytorze tekstu ręcznie usuń końce wierszy i utwórz jeden ciąg bez przerw i znaków końca wiersza, a następnie wklej go z powrotem do polecenia.
Jak uzyskać wszystkie etykiety z poziomu CLI
Istnieje specjalne polecenie, które tworzy etykiety z klastra:
openstack coe cluster template show k8s-stable-1.23.5 -c labels -f yaml
Tak wygląda wynik:
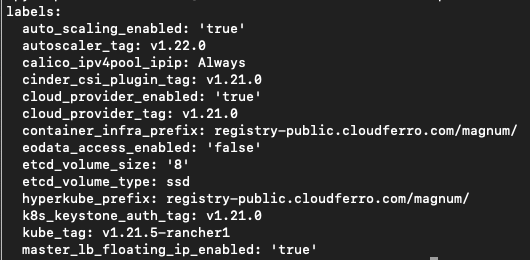
Jest to format yaml, określony przez parametr -f. Wiersze reprezentują wartości etykiet, a następnym działaniem jest utworzenie jednego długiego ciągu bez podziałów na wiersze, jak w poprzednim przykładzie, a następnie utworzenie polecenia CLI.
Używanie ciągu etykiet podczas tworzenia klastra w Horizon
Długi ciąg etykiet można również wykorzystać podczas ręcznego tworzenia klastra, czyli z poziomu interfejsu Horizon. Miejsce wstawienia tych etykiet opisano w Kroku 4 Definiowanie etykiet w sekcji Wymagania wstępne nr2.
Co można zrobić dalej?
Automatyczne skalowanie jest podobne do automatycznego naprawiania klastrów Kubernetes, obie te funkcje zapewniają automatyzację. Zapewniają również, że system będzie automatycznie korygować ustawienia dopóki będzie mieścił się w swoich podstawowych parametrach. Korzystaj z automatycznego skalowania zasobów klastra tak często, jak to tylko możliwe.