Wdrażanie obciążeń vGPU w Kubernetes w NSIS
Wykorzystanie procesorów graficznych (GPU) stanowi wysoce wydajną alternatywę dla szybkiego, wysoce równoległego przetwarzania wymagających zadań obliczeniowych, takich jak przetwarzanie EODATA, uczenie maszynowe i wiele innych.
W środowisku chmurowym wirtualne jednostki GPU (vGPU) są dostępne w niektórych wersjach maszyn wirtualnych. Niniejszy przewodnik zawiera instrukcje dotyczące dołączania takich maszyn wirtualnych z GPU jako węzłów klastra Kubernetes i korzystania z vGPU z podów Kubernetes.
Przedstawimy trzy alternatywne sposoby dodawania funkcji vGPU do klastra Kubernetes w oparciu o wymagany scenariusz. W przypadku każdego z nich powinieneś być w stanie zweryfikować instalację vGPU i przetestować ją, uruchamiając obciążenie vGPU.
Co zostanie omówione?
Scenariusz nr 1 - dodanie węzłów vGPU jako grupy węzłów w klastrach Kubernetes bez GPU utworzonych po 21 czerwca 2023r.
Scenariusz nr 2 - dodanie węzłów vGPU jako nodegroups w klastrach Kubernetes bez GPU utworzonych przed 21 czerwca 2023r.
Scenariusz nr 3 - Utworzenie nowego klastra Kubernetes z obsługą GPU i domyślną grupą węzłów z włączoną obsługą vGPU.
Weryfikacja instalacji vGPU
Test obciążenia vGPU
Dodanie grupy węzłów innej niż GPU do pierwszego klastra GPU
Wymagania wstępne
Nr 1 Hosting
Wymagane jest konto hostingowe NSIS z interfejsem Horizon https://horizon.cloudferro.com.
Nr 2 Znajomość plików RC i poleceń CLI dla Magnum
Jest wymagana znajomość korzystania z OpenStack CLI i Magnum CLI. Plik RC powinien być pozyskany i powinien wskazywać na projekt w OpenStack. Zobacz artykuł
Jak zainstalować klientów OpenStack i Magnum dla interfejsu wiersza poleceń w NSIS Horizon?.
Informacja
Jeśli podczas tworzenia nodegroups vGPU korzystasz z CLI , a uwierzytelnianie jest zapewniane za pomocą poświadczeń aplikacji, upewnij się, że poświadczenia zostały utworzone z ustawieniem
unrestricted: true
Nr 3 Działający klaster i kubectl
Aby połączyć się z klastrem za pomocą narzędzia kubectl, przeczytaj artykuł Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu przy użyciu Kubectl na NSIS OpenStack Magnum?.
Nr 4 Znajomość pojęcia nodegroups
Tworzenie dodatkowych nodegroups w klastrze Kubernetes na platformie NSIS OpenStack Magnum.
Flavory z vGPU w chmurach
Poniżej znajduje się lista flavorów z GPU w każdej z chmur, które mogą być używane z usługą Magnum Kubernetes.
- WAW3-1
WAW3-1 obsługuje zarówno cztery flavory z GPU oraz Kubernetes za pośrednictwem OpenStack Magnum.
Nazwa
RAM (MB)
Dysk (GB)
Jednostki vCPU
vm.a6000.1
14336
40
2
vm.a6000.2
28672
80
4
vm.a6000.3
57344
160
8
vm.a6000.4
114688
320
16
- WAW3-2
Są to flavory z vGPU dla WAW3-2 i Kubernetes za pośrednictwem OpenStack Magnum:
Nazwa
Jednostki vCPU
RAM
Całkowita ilość miejsca na dysku
Publiczny
vm.l40s.1
4
14,9 GB
40 GB
Tak
vm.l40s.8
32
119,22 GB
320 GB
Tak
gpu.l40sx2
64
238,44 GB
512 GB
Tak
gpu.l40sx8
254
953,75 GB
1000 GB
Tak
- FRA1-2
FRA1-2 obsługuje L40S i Kubernetes za pośrednictwem OpenStack Magnum.
Nazwa
Jednostki vCPU
RAM
Całkowita ilość miejsca na dysku
Publiczny
vm.l40s.2
8
29,8 GB
80 GB
Tak
vm.l40s.8
32
119,22 GB
320 GB
Tak
Porównanie RTX A6000 i NVIDIA L40S
Akcelerator graficzny NVIDIA L40S został zaprojektowany z myślą o operacjach w korporacyjnych centrach danych w trybie 24x7 i zoptymalizowany pod kątem wdrożeń na dużą skalę. W porównaniu do modelu A6000, NVIDIA L40S jest lepsza dla zastosowań takich jak:
zadania przetwarzania równoległego
obciążenia związane ze sztuczną inteligencją,
aplikacje ray tracingu w czasie rzeczywistym i jest
szybsza w zadaniach wymagających dużej ilości pamięci.
Specyfikacja |
NVIDIA RTX A60001 |
NVIDIA L40S1 |
|---|---|---|
Architektura |
Ampere |
Ada Lovelace |
Data wprowadzenia na rynek |
2020 |
2023 |
Rdzenie CUDA |
10752 |
18176 |
Pamięć |
48GB pamięci GDDR6 (przepustowość 768GB/s) |
48 GB pamięci GDDR6 (przepustowość 864 GB/s) |
Przyspieszenie taktowania |
Do 1800 MHz |
Do 2520 MHz |
Rdzenie tensorowe |
336 (3. generacja) |
568 (4. generacja) |
Wydajność |
Wysoka wydajność przy różnych obciążeniach |
Doskonała wydajność sztucznej inteligencji i uczenia maszynowego |
Przypadki zastosowania |
Renderowanie 3D, edycja wideo, rozwój sztucznej inteligencji |
Centra danych, sztuczna inteligencja na dużą skalę, aplikacje korporacyjne |
Scenariusz 1 - Dodanie węzłów vGPU jako grupy węzłów w klastrach Kubernetes bez GPU utworzonych po 21 czerwca 2023r.
Aby utworzyć nową grupę węzłów o nazwie gpu z jednym węzłem vGPU, na przykład vm.a6000.2, możemy użyć następującego polecenia Magnum CLI:
openstack coe nodegroup create __DOLLAR_SIGN__CLUSTER_ID gpu \
--labels "worker_type=gpu" \
--merge-labels \
--role worker \
--flavor vm.a6000.2 \
--node-count 1
Dostosuj parametry node-count i flavor do swoich preferencji, dostosuj __DOLLAR_SIGN__CLUSTER_ID do jednego ze swoich klastrów (można go pobrać z widoku klastrów w interfejsie użytkownika Horizon) i upewnij się, że rola jest ustawiona jako worker.
Kluczowym ustawieniem jest dodanie etykiety worker_type=gpu:
Twoje żądanie zostanie zaakceptowane:

Teraz wyświetl listę dostępnych nodegroups:
openstack coe nodegroup list __DOLLAR_SIGN__CLUSTER_ID_RECENT \
--max-width 120
Otrzymujemy następujące wyniki:

W rezultacie w klastrze została utworzona nowa grupa węzłów o nazwie gpu, która wykorzystuje flavor z GPU.
Scenariusz 2 - Dodanie węzłów vGPU jako nodegroups w klastrach Kubernetes bez GPU utworzonych przed 21 czerwca 2023r.
Instrukcje są takie same jak w poprzednim scenariuszu z wyjątkiem dodania dodatkowej etykiety:
existing_helm_handler_master_id=__DOLLAR_SIGN__MASTER_0_SERVER_ID
gdzie __DOLLAR_SIGN__MASTER_0_SERVER_ID to identyfikator maszyny wirtualnej master0 z klastra. Wartość uuid można uzyskać:
w Horizon, w widoku Instances
lub za pomocą polecenia CLI, aby wyodrębnić uuid dla węzła głównego:
openstack coe nodegroup list __DOLLAR_SIGN__CLUSTER_ID_OLDER \
-c uuid \
-c name \
-c status \
-c role

W tym przykładzie uuid to 413c7486-caa9-4e12-be3b-3d9410f2d32f. Ustaw wartość etykiety głównego węzła:
export MASTER_0_SERVER_ID="413c7486-caa9-4e12-be3b-3d9410f2d32f"
i wykonaj następujące polecenie, aby utworzyć dodatkową grupę węzłów w tym scenariuszu:
openstack coe nodegroup create __DOLLAR_SIGN__CLUSTER_ID_OLDER gpu \
--labels "worker_type=gpu,existing_helm_handler_master_id=__DOLLAR_SIGN__MASTER_0_SERVER_ID" \
--merge-labels \
--role worker \
--flavor vm.a6000.2 \
--node-count 1
Pomiędzy etykietami nie może być odstępu.
Żądanie zostanie zaakceptowane i po chwili dostępna będzie nowy nodegroup oparty na flavorze z GPU. Listę nodegroups można wyświetlić za pomocą polecenia:
openstack coe nodegroup list __DOLLAR_SIGN__CLUSTER_ID_OLDER --max-width 120
Scenariusz 3 - Utworzenie nowego klastra Kubernetes z obsługą GPU i domyślną grupą węzłów z włączoną obsługą vGPU
Aby utworzyć nowy klaster z obsługą vGPU, można użyć zwykłych poleceń Horizon, wybierając jeden z istniejących szablonów, któego nazwa zawiera vgu:
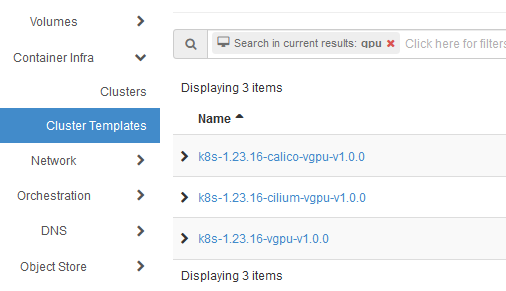
W poniższym przykładzie używamy CLI do utworzenia klastra o nazwie k8s-gpu-with_template z użyciem szablonu k8s-1.23.16-vgpu-v1.0.0. Przykładowy klaster ma:
jeden węzeł główny z flavorem eo1.medium i
jeden węzeł roboczy z flavorem vm.a6000.2 z włączoną obsługą vGPU.
Aby dostosować te parametry do swoich wymagań, należy zastąpić __DOLLAR_SIGN__KEYPAIR własnym parametrem. Ponadto, aby sprawdzić, czy etykiety nvidia są poprawnie zainstalowane, najpierw utwórz przestrzeń nazw o nazwie nvidia-device-plugin. Następnie można wyświetlić listę przestrzeni nazw, aby upewnić się, że została ona utworzona poprawnie. Tak więc polecenia przygotowawcze wyglądają następująco:
export KEYPAIR="sshkey"
kubectl create namespace nvidia-device-plugin
kubectl get namespaces
Ostatnim poleceniem służącym do utworzenia wymaganego klastra jest:
openstack coe cluster create k8s-gpu-with_template \
--cluster-template "k8s-1.23.16-vgpu-v1.0.0" \
--keypair=__DOLLAR_SIGN__KEYPAIR \
--master-count 1 \
--node-count 1
Weryfikacja instalacji vGPU
Możesz zweryfikować, czy węzły obsługujące vGPU zostały poprawnie dodane do klastra, sprawdzając nvidia-device-plugin wdrożony w klastrze w przestrzeni nazw nvidia-device-plugin. Polecenie wyświetlające zawartość przestrzeni nazw nvidia to:
kubectl get daemonset nvidia-device-plugin \
-n nvidia-device-plugin

Zobacz, które węzły są teraz obecne:
kubectl get node

Każdy węzeł z GPU powinien mieć dodanych kilka etykiet nvidia. Aby to sprawdzić, możesz uruchomić jedno z poniższych poleceń, z których drugie pokaże sformatowane etykiety:
kubectl get node k8s-gpu-cluster-XXXX --show-labels
kubectl get node k8s-gpu-cluster-XXXX \
-o go-template='{{range __DOLLAR_SIGN__key, __DOLLAR_SIGN__value := .metadata.labels}}{{__DOLLAR_SIGN__key}}: {{__DOLLAR_SIGN__value}}{{"\n"}}{{end}}'
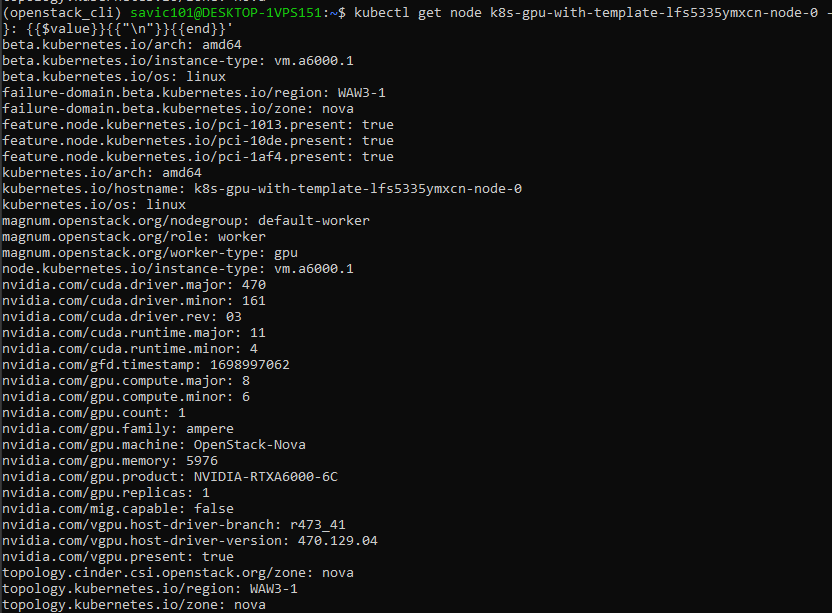
Konkretnie, w naszym przypadku drugie polecenie to:
kubectl get node k8s-gpu-with-template-lfs5335ymxcn-node-0 \
-o go-template='{{range __DOLLAR_SIGN__key, __DOLLAR_SIGN__value := .metadata.labels}}{{__DOLLAR_SIGN__key}}: {{__DOLLAR_SIGN__value}}{{"\n"}}{{end}}'
Jego wynik będzie wyglądał następująco:
Ponadto węzły z GPU są domyślnie oznaczone jako:
node.cloudferro.com/type=gpu:NoSchedule
Można to sprawdzić, uruchamiając poniższe polecenie, w którym używamy nazwy istniejącego węzła:
kubectl describe node k8s-gpu-with-template-lfs5335ymxcn-node-0 | grep 'Taints'
Uruchomienie testu obciążenie vGPU
Możemy uruchomić przykładowe obciążenie na vGPU. Aby to zrobić, utwórz plik manifestu YAML vgpu-pod.yaml o następującej zawartości:
vgpu-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 vGPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- effect: NoSchedule
key: node.cloudferro.com/type
operator: Equal
value: gpu
Zastosuj zmiany za pomocą:polecenia:
kubectl apply -f vgpu-pod.yaml

Ten pod zażąda jednego vGPU, więc efektywnie wykorzysta jednostkę vGPU przydzieloną do pojedynczego węzła. Na przykład, jeśli masz klaster z 2 węzłami obsługującymi vGPU, możesz uruchomić 2 pody żądające po 1 vGPU każdy.
Ponadto, aby zaplanować pody na GPU, należy zastosować dwie tolerancje, jak w powyższym przykładzie, co w praktyce oznacza, że pod będzie zaplanowany tylko na węzłach z GPU.
Patrząc na logi, widzimy, że zadanie rzeczywiście zostało wykonane:
kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Dodanie grupy węzłów innej niż GPU do pierwszego klastra GPU
Odnosimy się do klastrów GPU-first jako klastrów utworzonych z flagą worker_type=gpu. Przykładowo, w klastrze utworzonym według scenariusza nr3, domyślna grupa węzłów składa się z węzłów vGPU.
W takich klastrach, aby dodać dodatkową grupę węzłów bez procesora graficznego, należy:
określić identyfikator obrazu systemu, który zarządza tą grupą węzłów.
dodać etykietę worker_type=default
upewnić się, że flavor dla tej grupy węzłów jest inny niż flavor z GPU.
Aby pobrać identyfikator obrazu, musisz wiedzieć, za pomocą którego szablonu chcesz utworzyć nową grupę węzłów. Z istniejących szablonów innych niż GPU wybieramy dla tego przykładu k8s-1.23.16-v1.0.2. Uruchom następujące polecenie, aby wyodrębnić identyfikator szablonu, ponieważ będzie on potrzebny do utworzenia grupy węzłów:
openstack coe cluster \
template show k8s-1.23.16-v1.0.2 | grep image_id
W naszym przypadku daje to następujący wynik:

Następnie możemy dodać grupę węzłów bez GPU za pomocą poniższego polecenia, w którym można dostosować parametry. W naszym przykładzie używamy nazwy klastra ze scenariusza 3 (świeżo utworzonego obsługą z GPU) powyżej i ustawiamy flavor węzła roboczego na eo1.medium:
export CLUSTER_ID="k8s-gpu-with_template"
export IMAGE_ID="42696e90-57af-4124-8e20-d017a44d6e24"
openstack coe nodegroup create __DOLLAR_SIGN__CLUSTER_ID default \
--labels "worker_type=default" \
--merge-labels \
--role worker \
--flavor "eo1.medium" \
--image __DOLLAR_SIGN__IMAGE_ID \
--node-count 1
Następnie wyświetl zawartość grupy węzłów, aby sprawdzić, czy utworzenie się powiodło:
openstack coe nodegroup list __DOLLAR_SIGN__CLUSTER_ID \
--max-width 120
