Tworzenie kopii zapasowych klastra Kubernetes przy użyciu Velero
Czym jest Velero
Velero to oficjalny projekt open source firmy VMware. Velero może tworzyć kopie zapasowe wszystkich obiektów Kubernetes API i trwałych woluminów z klastra, na którym jest zainstalowany. Zarchiwizowane obiekty można przywrócić na tym samym lub na nowym klastrze. Korzystanie z pakietu takiego jak Velero jest niezbędne dla każdego poważnego developmentu w klastrze Kubernetes.
Zasadniczo tworzysz magazyn obiektów w OpenStack, używając Horizon lub modułu Swift polecenia openstack, a następnie zapisujesz w nim stan klastra. Przywracanie jest takie samo w odwrotnej kolejności - odczyt z tego magazynu obiektów i zapisanie go w klastrze Kubernetes.
Velero ma własny system poleceń CLI, dzięki czemu możliwe jest zautomatyzowanie tworzenia kopii zapasowych za pomocą zadań cron.
Co zostanie omówione?
Pobieranie poświadczeń klienta EC2
Dostosowanie pliku konfiguracyjnego „values.yaml”
Tworzenie przestrzeni nazw o nazwie velero w celu uzyskania precyzyjnego dostępu do klastra Kubernetes
Instalowanie Velero za pomocą wykresu Helm
Instalowanie i usuwanie kopii zapasowych przy użyciu Velero
Przykład 1 Podstawy przywracania aplikacji
Przykład 2 Migawka przywracania aplikacji
Wymagania wstępne
Nr 1 Hosting
Wymagane jest konto hostingowe NSIS z interfejsem Horizon https://horizon.cloudferro.com.
Zasoby, których potrzebujesz i używasz, będą odzwierciedlały stan Twojego portfela konta. Sprawdź stan swojego konta na stronie https://NSIS-Cloudcloud-innovation.cloudferro.com/login.
Nr 2 Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu
Zakładamy również, że masz jeden lub więcej gotowych klastrów Kubernetes, dostępnych za pośrednictwem polecenia kubectl:
Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu przy użyciu Kubectl na NSIS OpenStack Magnum?
Wynikiem tego artykułu będzie ustawienie zmiennej systemowej KUBECONFIG, która wskazuje na plik konfiguracyjny dostępu do chmury Kubernetes. Typowym poleceniem będzie:
export KUBECONFIG=/home/username/Desktop/kubernetes/k8sdir/config
W przypadku, gdy po raz pierwszy korzystasz z tego konkretnego pliku konfiguracyjnego, zwiększ jego bezpieczeństwo, wykonując również następujące polecenie:
chmod 600 /home/username/Desktop/kubernetes/k8sdir/config
Nr 3 Obsługa narzędzia Helm
Aby zainstalować Velero, użyjemy narzędzia Helm:
Wdrażanie Helm Charts na klastrach Magnum Kubernetes w chmurze NSIS.
Nr 4 Dostępna obiektowa pamięć masowa S3
Aby ją utworzyć, można uzyskać dostęp do obiektowej pamięci masowej za pomocą interfejsu Horizon lub CLI.
Polecenia Horizon
- CLI
Do pracy z obiektową pamięcią masową można również użyć polecenia takiego jak
openstack container
Więcej informacji można znaleźć w artykule Jak uzyskać dostęp do object storage za pomocą OpenStack CLI na NSIS.
Tak czy inaczej, zakładamy, że istnieje kontener o nazwie „bucketnew”:
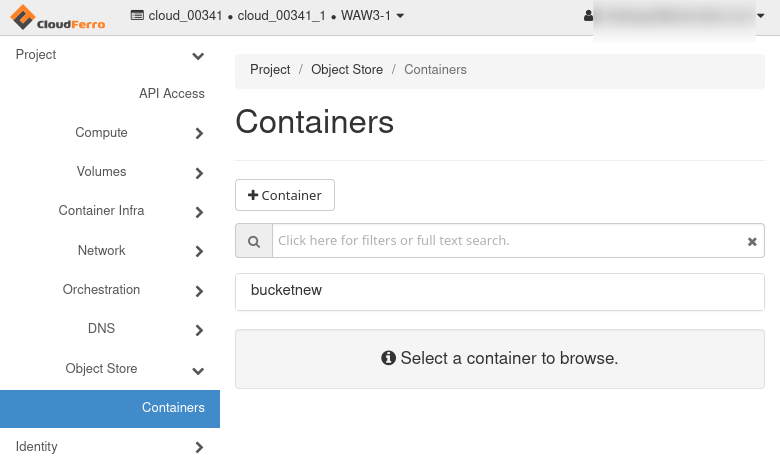
Podczas pracy z tym artykułem podaj własną unikalną nazwę.
Przed instalacją Velero
Zainstalujemy Velero na Ubuntu 22.04; korzystanie z innych dystrybucji Linuksa będzie podobne.
Zaktualizuj swoje środowisko Ubuntu:
sudo apt update && sudo apt upgrade
Konieczny będzie dostęp do klastra Kubernetes w wersji 1.16 lub nowszej z włączoną obsługą DNS i sieci kontenerów. Aby uzyskać więcej informacji na temat obsługiwanych wersji Kubernetes, zobacz Velero compatibility matrix.
Krok instalacji 1 Uzyskanie poświadczeń klienta EC2
Najpierw pobierz poświadczenia EC2 z OpenStack. Są one niezbędne do uzyskania dostępu do prywatnego zasobnika (kontenera). Wygeneruj je samodzielnie, wykonując następujące polecenia:
openstack ec2 credentials create
openstack ec2 credentials list
Zapisz Klucz dostępu i Klucz tajny. Będą one potrzebne w następnym kroku, w którym należy skonfigurować plik konfiguracyjny Velero.
Krok instalacji 2 Dostosowanie pliku konfiguracyjnego - „values.yaml”
Teraz utwórz lub dostosuj plik konfiguracyjny dla Velero. Aby utworzyć ten plik, użyj wybranego edytora tekstu, . Na przykład w systemie MacOS lub Linux można użyć nano, jak poniżej:
sudo nano values.yaml
Użyj pliku konfiguracyjnego przedstawionego poniżej. Wypełnij wymagane pola, które są oznaczone znakami ##:
values.yaml
initContainers: - name: velero-plugin-for-aws image: velero/velero-plugin-for-aws:v1.4.0 imagePullPolicy: IfNotPresent volumeMounts: - mountPath: /target name: plugins configuration: provider: aws backupStorageLocation: provider: aws name: ## enter name of backup storage location (could be anything) bucket: ## enter name of bucket created in openstack default: true config: region: default s3ForcePathStyle: true s3Url: ## enter URL of object storage (for example "https://s3.waw4-1.cloudferro.com") credentials: secretContents: ## enter access and secret key to ec2 bucket. This configuration will create kubernetes secret. cloud: | [default] aws_access_key_id= aws_secret_access_key= ##existingSecret: ## If you want to use existing secret, created from sealed secret, then use this variable and omit credentials.secretContents. snapshotsEnabled: false deployRestic: true restic: podVolumePath: /var/lib/kubelet/pods privileged: true schedules: mybackup: disabled: false schedule: "0 6,18 * * *" ## choose time, when scheduled backups will be make. template: ttl: "240h" ## choose ttl, after which the backups will be removed. snapshotVolumes: false
Wklej zawartość do pliku konfiguracyjnego values.yaml i zapisz go.
Przykład już skonfigurowanego pliku:
initContainers: - name: velero-plugin-for-aws image: velero/velero-plugin-for-aws:v1.4.0 imagePullPolicy: IfNotPresent volumeMounts: - mountPath: /target name: plugins configuration: provider: aws backupStorageLocation: provider: aws name: velerobackuptesting bucket: bucket default: true config: region: default s3ForcePathStyle: true s3Url: s3.waw4-1.cloudferro.com credentials: secretContents: ## enter access and secret key to ec2 bucket. This configuration will create kubernetes secret. cloud: | [default] aws_access_key_id= c4b4ee62a18f4e0ba23f71629d2038e1x aws_secret_access_key= dee1581dac214d3dsa34037e826f9148 ##existingSecret: ## If you want to use existing secret, created from sealed secret, then use this variable and omit credentials.secretContents. snapshotsEnabled: false deployRestic: true restic: podVolumePath: /var/lib/kubelet/pods privileged: true schedules: mybackup: disabled: false schedule: "0 * * *" template: ttl: "168h" snapshotVolumes: false
Krok instalacji 3 Tworzenie przestrzeni nazw
Velero musi być zainstalowane w przestrzeni nazw velero. Oto polecenie do jej utworzenia:
kubectl create namespace velero
namespace/velero created
Krok instalacji 4 Instalacja Velero z wykresem Helm
Poniżej znajdują się polecenia instalacji Velero za pomocą wykresu Helm:
helm repo add vmware-tanzu https://vmware-tanzu.github.io/helm-charts
Wynik jest następujący:
"vmware-tanzu" has been added to your repositories
Poniższe polecenie zainstaluje velero w klastrze:
helm install vmware-tanzu/velero --namespace velero --version 2.28 -f values.yaml --generate-name
Wynik będzie wyglądał następująco:
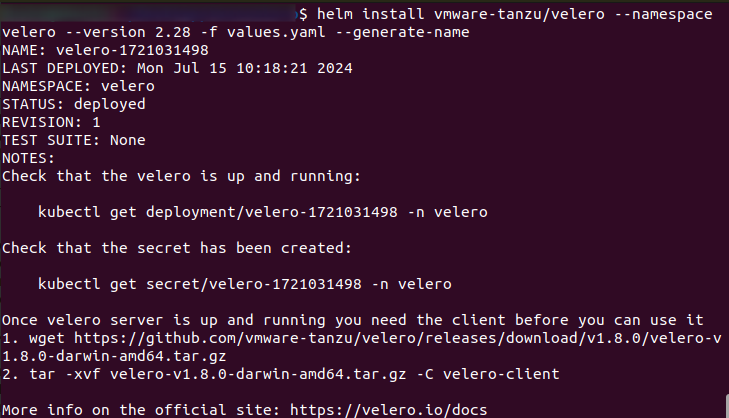
Aby zobaczyć wersję Velero, która jest faktycznie zainstalowana, użyj polecenia:
helm list --namespace velero
Zanotuj użytą nazwę velero-1721031498, której będziemy używać w dalszej części artykułu. W twoim przypadku zanotuj poprawną nazwę velero i zamień ją wartość 1721031498.
Oto jak sprawdzić, czy Velero działa:
kubectl get deployment/velero-1721031498 -n velero
Wynik będzie podobny do tego:
NAME READY UP-TO-DATE AVAILABLE AGE
velero-1721031498 1/1 1 1 5m30s
Sprawdź, czy tajny klucz został utworzony:
kubectl get secret/velero-1721031498 -n velero
Rezultat jest następujący:
NAME TYPE DATA AGE
velero-1721031498 Opaque 1 3d1h
Krok instalacji 5 Instalacja Velero CLI
Ostatnim krokiem jest zainstalowanie Velero CLI - interfejsu wiersza poleceń odpowiedniego do pracy z okna terminala w systemie operacyjnym.
Pobierz klienta określonego dla twojego systemu operacyjnego ze strony: https://github.com/vmware-tanzu/velero/releases, używając wget. Tutaj pobieramy wersję
velero-v1.9.1-linux-amd64.tar.gz,
ale zaleca się pobranie najnowszej wersji. W takim przypadku należy odpowiednio zmienić nazwę pliku tar.gz.
wget https://github.com/vmware-tanzu/velero/releases/download/v1.9.1/velero-v1.9.1-linux-amd64.tar.gz
Rozpakuj plik tarball:
tar -xvf velero-v1.9.1-linux-amd64.tar.gz
Oczekiwany rezultat jest następujący:
velero-v1.9.1-linux-amd64/LICENSE
velero-v1.9.1-linux-amd64/examples/README.md
velero-v1.9.1-linux-amd64/examples/minio
velero-v1.9.1-linux-amd64/examples/minio/00-minio-deployment.yaml
velero-v1.9.1-linux-amd64/examples/nginx-app
velero-v1.9.1-linux-amd64/examples/nginx-app/README.md
velero-v1.9.1-linux-amd64/examples/nginx-app/base.yaml
velero-v1.9.1-linux-amd64/examples/nginx-app/with-pv.yaml
velero-v1.9.1-linux-amd64/velero
Przenieś wyodrębniony plik binarny velero do lokalizacji w $PATH (/usr/local/bin dla większości użytkowników):
cd velero-v1.9.1-linux-amd64
# System might force using sudo
sudo mv velero /usr/local/bin
# check if velero is working
velero version

Po tych operacjach powinno być możliwe korzystanie z poleceń velero. Aby uzyskać pomoc, jak z nich korzystać, wykonaj polecenie:
velero help
Praca z Velero
Do tej pory:
utworzyliśmy obiektową pamięć masową o nazwie „bucketnew” i
wskazaliśmy velero, aby używał jej poprzez parametr bucket: w pliku values.yaml.
Velero utworzy kolejną obiektową pamięć masową o nazwie backups pod „bucketnew”, a następnie będzie kontynuować tworzenie obiektowych pamięci masowych dla poszczególnych kopii zapasowych. Na przykład poniższe polecenie doda obiektową pamięć masową o nazwie mybackup2:
velero backup create mybackup2 Backup request "mybackup2" submitted successfully.
Oto jak będzie to wyglądać w Horizon:
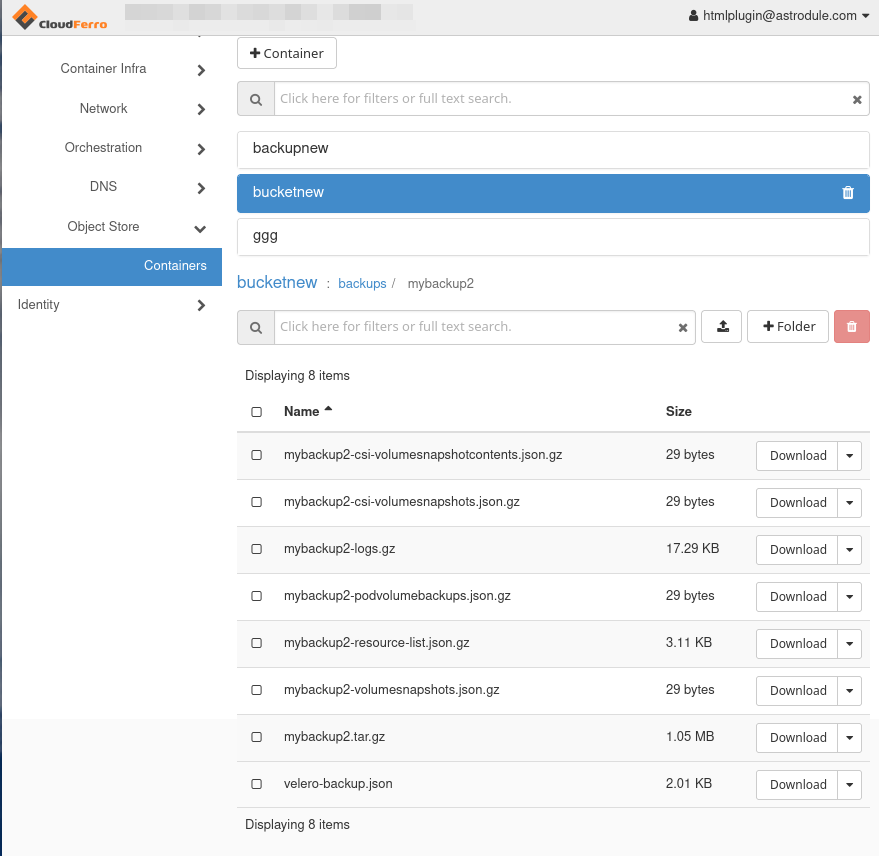
Dodajmy jeszcze dwie kopie zapasowe. Pierwsza z nich powinna tworzyć kopie zapasowe wszystkich obiektów API w przestrzeni nazw velero:
velero backup create mybackup3 --include-namespaces velero
Drugi wykona kopię zapasową wszystkich obiektów API w domyślnej przestrzeni nazw
velero backup create mybackup5 --include-namespaces default
Backup request "mybackup4" submitted successfully.
Po wykonaniu tych trzech kopii zapasowych struktura obiektowej pamięci masowej jest następująca:

Można również użyć polecenia velero CLI, aby wyświetlić listę istniejących kopii zapasowych:
velero backup get
Wynik w oknie terminala jest następujący:
Przykład 1 Podstawy przywracania aplikacji
Zademonstrujmy teraz, jak przywrócić aplikację Kubernetes. Najpierw sklonujmy jedną przykładową aplikację z GitHub. Wykonaj to polecenie:
git clone https://github.com/vmware-tanzu/velero.git
Cloning into 'velero'...
Resolving deltas: 100% (27049/27049), done.
cd velero
Uruchom przykładową aplikację nginx:
kubectl apply -f examples/nginx-app/base.yaml
kubectl apply -f base.yaml
namespace/nginx-example unchanged
deployment.apps/nginx-deployment unchanged
service/my-nginx unchanged
Utwórz kopię zapasową:
velero backup create nginx-backup --include-namespaces nginx-example
Backup request "nginx-backup" submitted successfully.
Tak wygląda kopia zapasowa nginx-backup w Horizon:
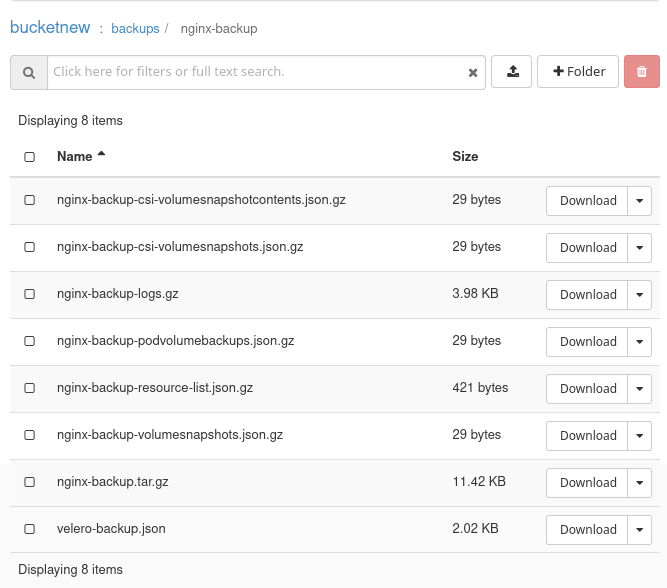
Zasymuluj krytyczną awarię:
kubectl delete namespaces nginx-example
# Wait for the namespace to be deleted
namespace "nginx-example" deleted
Przywróć utracone zasoby:
velero restore create --from-backup nginx-backup
Restore request "nginx-backup-20220728013338" submitted successfully.
Run `velero restore describe nginx-backup-20220728013338` or `velero restore logs nginx-backup-20220728013338` for more details.
velero backup get
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
backup New 0 0 <nil> n/a <none>
nginx-backup New 0 0 <nil> n/a <none>
Przykład 2 Migawka przywracania aplikacji
Uruchom przykładową aplikację nginx:
kubectl apply -f examples/nginx-app/with-pv.yaml
namespace/nginx-example created
persistentvolumeclaim/nginx-logs created
deployment.apps/nginx-deployment created
service/my-nginx created
Utwórz kopię zapasową ze snapshotami woluminów trwałych:
velero backup create nginx-backup-vp --include-namespaces nginx-example
Backup request "nginx-backup" submitted successfully.
Run `velero backup describe nginx-backup` or `velero backup logs nginx-backup` for more details.
Zasymuluj krytyczną awarię:
kubectl delete namespaces nginx-example
namespace "nginx-example" deleted
Ważne
Ponieważ domyślną zasadą odzyskiwania <https://kubernetes.io/docs/concepts/storage/persistent-volumes/#reclaiming>`_ dla dynamicznie dostarczanych trwałych woluminów jest „Delete”, polecenia te powinny spowodować, że dostawca usług w chmurze usunie dysk, na którym znajduje się kopia zapasowa woluminu trwałego. Usuwanie jest wykonywane asynchronicznie, więc może to zająć trochę czasu.
Przywróć utracone zasoby:
velero restore create --from-backup nginx-backup-vp
Restore request "nginx-backup-20220728015234" submitted successfully.
Run `velero restore describe nginx-backup-20220728015234` or `velero restore logs nginx-backup-20220728015234` for more details.
Usuń kopię zapasową Velero
Istnieją dwa sposoby usuwania kopii zapasowych tworzonych przez Velero.
- Usunięcie tylko kopii zapasowej zasobu niestandardowego
kubectl delete backup <backupName> -n <veleroNamespace>
usunięcie tylko kopii zapasowej zasobu niestandardowego i bez usuwania żadnych powiązanych danych z obiektowej/blokowej pamięci masowej.
- Usunięcie wszystkich danych z obiektowej/blokowej pamięci masowej
velero backup delete <backupName>
usunie kopię zapasową zasobuj, w tym wszystkie dane w obiektowej/blokowej pamięci masowej
Usuwanie Velero z klastra
Odinstalowanie Velero
Aby odinstalować wersję Velero:
helm uninstall velero-1721031498 --namespace velero
Aby usunąć przestrzeń nazw Velero
kubectl delete namespace velero
Co można zrobić dalej?
Teraz, gdy Velero jest już uruchomiony, możesz zintegrować go ze swoją procedurą. Velero będzie przydatny we wszystkich klasycznych scenariuszach tworzenia kopii zapasowych - do odzyskiwania po awarii, migracji klastra i przestrzeni nazw, testowania i developmentu, wycofywania aplikacji, zapewnienia zgodności z przepisami, audytu itp. Oprócz tych szerokich przypadków zastosowania Velero będzie pomocy w konkretnych zadaniach klastra Kubernetes związanych z tworzeniem kopii zapasowych, takich jak:
tworzenie kopii zapasowych i przywracanie wdrożeń, usług, map konfiguracji i tajnych kodów,
selektywne kopie zapasowe, na przykład tylko dla określonych przestrzeni nazw lub selektorów etykiet,
wykonywanie migawek woluminów przy użyciu interfejsów API dostawcy usług w chmurze (AWS, Azure, GCP itp.).
wykonywanie migawek trwałych woluminów w celu odzyskiwania punktów w określonym czasie
zapisywanie kopii zapasowych danych w AWS S3, Google Cloud Storage, Azure Blob Storage itp.
integracja z poleceniem kubectl, dzięki czemu niestandardowe definicje zasobów (CRD) są używane do definiowania konfiguracji kopii zapasowych i ich przywracania.