Woluminowa i ulotna pamięć masowa dla klastrów Kubernetes OpenStack Magnum w NSIS Cloud
Kontenery w Kubernetes przechowują pliki na dysku, a jeśli kontener ulegnie awarii, dane zostaną utracone. Nowy kontener może zastąpić stary, ale dane nie przetrwają. Inny problem pojawia się, gdy kontenery uruchomione w podzie muszą współdzielić pliki.
W związku z tym Kubernetes ma inny sposób przechowywania plików, zwany woluminami. Mogą one być trwałe lub ulotne w odniesieniu do czasu życia poda:
Woluminy ulotne są usuwane, gdy pod jest usuwany, podczas gdy
woluminy trwałe nadal istnieją, nawet jeśli pod, do której są podłączone, już nie istnieje.
Koncepcja woluminów została po raz pierwszy spopularyzowana przez Docker, gdzie był to katalog na dysku lub w kontenerze. W hostingu OpenStack na NSIS domyślny magazyn Docker jest skonfigurowany tak, by korzystał z ulotnego dysku instancji. Można to zmienić, określając rozmiar woluminu Docker podczas tworzenia klastra symbolicznie w ten sposób (poniżej znajduje się pełne polecenie generowania nowego klastra przy użyciu parametru –docker-volume-size):
openstack coe cluster create --docker-volume-size 50
Oznacza to, że zostanie utworzony Persistent Volume o rozmiarze 50 GB, który zostanie dołączony do poda . Użycie parametru –docker-volume-size to sposób zarówno na zarezerwowanie miejsca, jak i zadeklarowanie, że pamięć masowa będzie trwała.
Co zostanie omówione?
Jak utworzyć klaster, gdy używany jest parametr –docker-volume-size
Jak utworzyć manifest dla poda z emptyDir jako woluminem
Jak utworzyć poda z tym manifestem
Jak wykonywać polecenia bash w kontenerze
Jak zapisać plik w pamięci trwałej
Jak wykazać, że dołączony wolumin jest trwały
Wymagania wstępne
1 Hosting
Wymagane jest konto hostingowe NSIS z interfejsem Horizon https://horizon.cloudferro.com.
2 Tworzenie klastrów za pomocą CLI
Artykuł Jak korzystać z interfejsu wiersza poleceń dla klastrów Kubernetes w NSIS OpenStack Magnum wprowadzi cię w tworzenie klastrów za pomocą interfejsu wiersza poleceń.
3 Podłączenie klienta openstack do chmury
Przygotuj klienty openstack i magnum, wykonując Krok 2 Podłączanie klientów OpenStack i Magnum do chmury Horizon z artykułu Jak zainstalować klientów OpenStack i Magnum dla interfejsu wiersza poleceń w NSIS Horizon?.
Nr 4 Sprawdzenie dostępnych kwot
Przed utworzeniem dodatkowego klastra sprawdź stan zasobów za pomocą poleceń Horizon Computer => Overview.
5 Klucze prywatne i publiczne
Para kluczy SSH utworzona w pulpicie nawigacyjnym OpenStack. Aby ją utworzyć, postępuj zgodnie z artykułem Jak utworzyć parę kluczy w OpenStack Dashboard na NSIS Cloud. Zostanie utworzona para kluczy o nazwie sshkey, której będzie można używać również w tym samouczku.
6 Rodzaje woluminów
Typy wolumenów są opisane w oficjalnej dokumentacji Kubernetes.
Krok 1 - Utworzenie klastra przy użyciu parametru –docker-volume-size
Utworzysz nowy klaster o nazwie dockerspace, który będzie używać parametru –docker-volume-size za pomocą następującego polecenia:
openstack coe cluster create dockerspace
--cluster-template k8s-1.23.16-cilium-v1.0.3
--keypair sshkey
--master-count 1
--node-count 2
--docker-volume-size 50
--master-flavor eo1.large
--flavor eo2.large
Po kilku minutach zostanie utworzony nowy klaster dockerspace.
Kliknij Container Infra => Clusters, aby wyświetlić trzy klastry istniejące w systemie: authenabled, k8s-cluster i dockerspace.
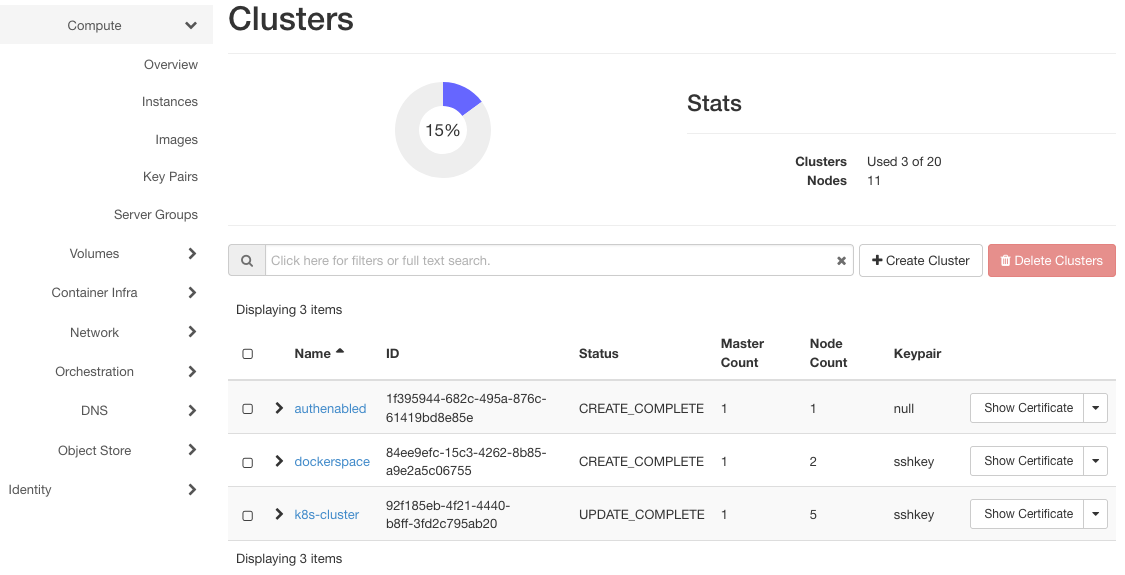
Oto ich instancje (widoczne po kliknięciu opcji Compute => Instances):
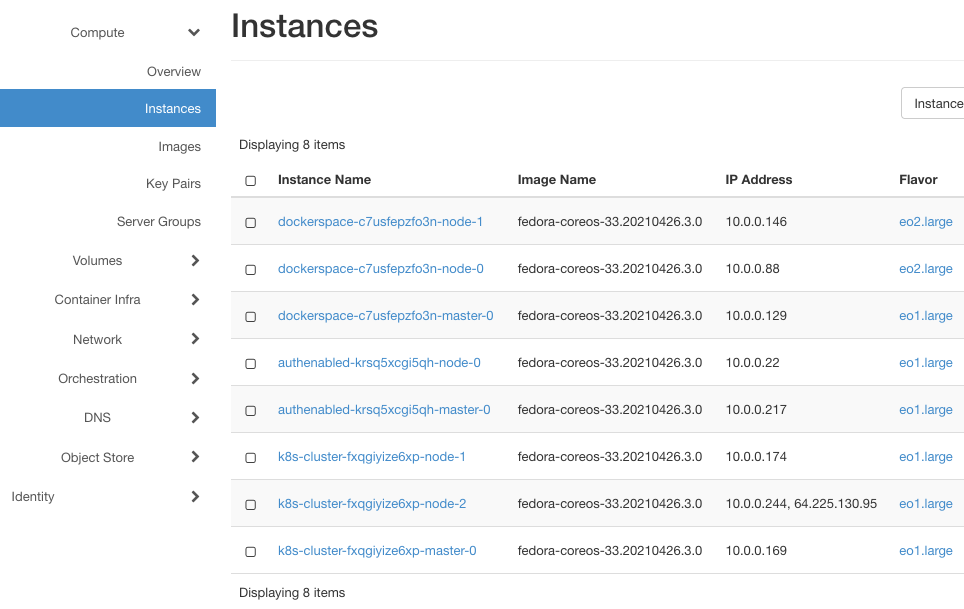
Każdy z nich będzie mieć co najmniej dwie instancje, jedną dla węzła głównego i jedną dla węzła roboczego. dockerspace ma trzy instancje, ponieważ ma dwa węzły robocze utworzone na podstawie obrazu eo2.large.
Jak dotąd to nic nadzwyczajnego. Kliknij opcję Volumes => Volumes, aby wyświetlić listę woluminów:
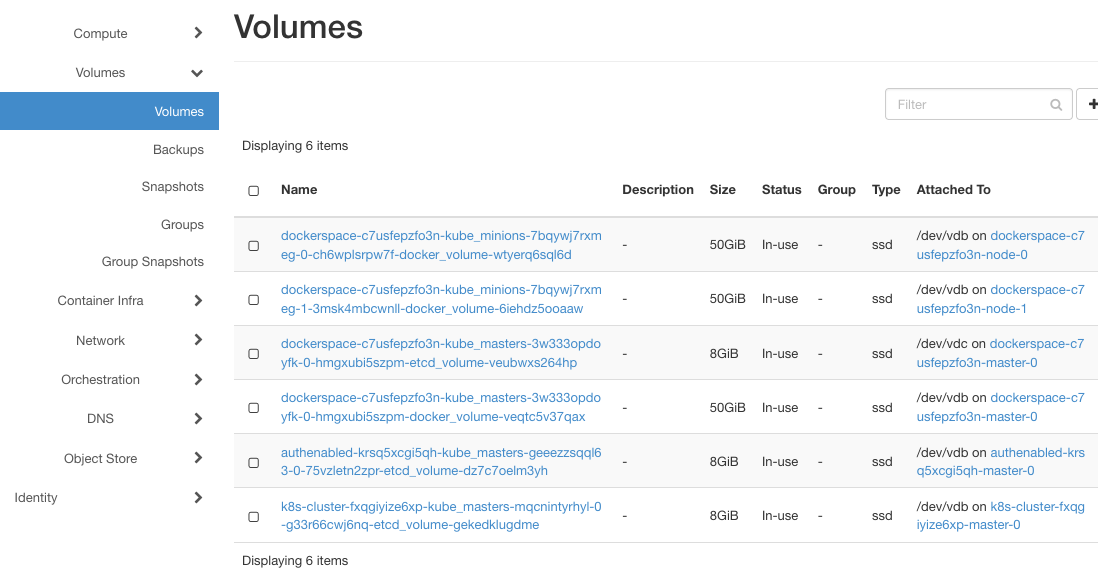
Jeśli parametr –docker-volume-size nie został użyty, pojawią się tutaj tylko instancje z etcd-volume w nazwie, tak jak w przypadku klastrów authenabled i k8s-cluster. Jeśli jest włączony, pojawią się dodatkowe woluminy, po jednym dla każdego węzła. dockerspace będzie zatem miał jedną instancję dla węzła głównego i dwie instancje dla węzłów roboczych.
Zwróć uwagę na kolumnę Attached. Wszystkie węzły dla dockerspace używają /dev/vdb do przechowywania danych, co będzie ważne później.
Jak określono podczas ich tworzenia, docker-volumes mają rozmiar 50 GB każdy.
W tym kroku został utworzony nowy klaster z włączonym docker storage, a następnie sprawdzono, że główna różnica polega na tworzeniu woluminów dla klastra.
Krok 2 - Utworzenie manifestu dla poda
Aby utworzyć pod, należy użyć pliku w formacie yaml, który definiuje parametry poda. Użyj polecenia
nano redis.yaml
aby utworzyć plik o nazwie redis.yaml i skopiować do niego następujące wiersze:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
Tak będzie on wyglądać w terminalu:
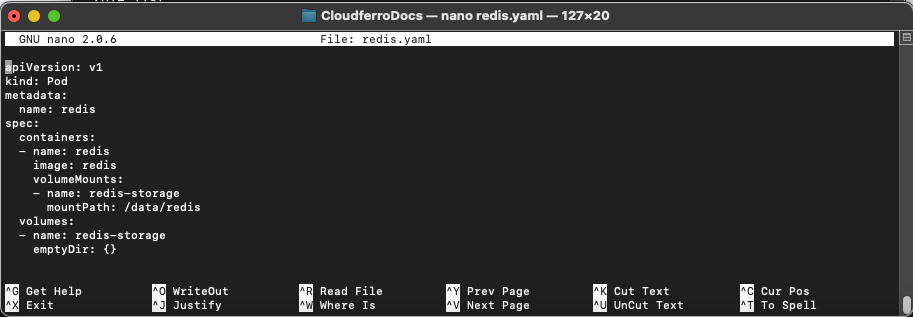
Tworzony jest pod o nazwie redis, będzie on zajmował jeden kontener o nazwie redis. Zawartością tego kontenera będzie obraz o nazwie redis.
Redis to dobrze znana baza danych, a jej obraz jest przygotowany z góry, więc można go pobrać bezpośrednio z repozytorium. Jeśli wdrażasz własną aplikację, najlepszym sposobem byłoby wydanie jej za pośrednictwem Dockera i pobranie jej z jego repozytorium.
Nowy wolumin zostanie nazwany redis-storage, a jego katalog będzie miał nazwę /data/redis. Wolumin będzie teżmiał nazwę redis-storage i będzie typu emptyDir.
Wolumin emptyDir jest początkowo pusty i jest tworzony po raz pierwszy, gdy Pod zostanie przypisany do węzła. Będzie istniał tak długo, jak ten pod będzie działał, a jeśli pod zostanie usunięty, powiązane dane w emptyDir zostaną trwale usunięte. Dane w woluminie emptyDir są jednak bezpieczne w przypadku awarii kontenera.
Oprócz emptyDir, można było użyć około tuzina innych typów woluminów, na przykład awsElasticBlockStore, azureDisk, cinder itd.
W tym kroku został przygotowany manifest pod, za pomocą którego w następnym kroku utworzysz pod.
Krok 3 - Utworzenia poda na węźle 0 dockerspace
W tym kroku zostanie utworzony nowy pod na węźle 0 klastra dockerspace.
Najpierw sprawdź, jakie pody są dostępne w klastrze:
kubectl get pods
Może to spowodować wyświetlenie wiersza z komunikatem o błędzie, takiego jak ten:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Stanie się tak, jeśli parametry kubectl nie zostały określone zgodnie z wymaganie wstępnymi nr 3. Teraz należy skonfigurować dostęp do dockerstate:
mkdir dockerspacedir
openstack coe cluster config
--dir dockerspacedir
--force
--output-certs
dockerspace
Najpierw utwórz nowy katalog dockerspacedir, w którym będzie znajdował się plik konfiguracyjny dostępu do klastra, a następnie wykonaj polecenie cluster config. Wynik będzie wyglądał następująco:
.. code::
export KUBECONFIG=/Users/duskosavic/CloudferroDocs/dockerspacedir/config
Skopiuj go i wprowadź ponownie jako polecenie w terminalu. Umożliwi do aplikacji kubectl dostęp do klastra. Utwórz pod za pomocą polecenia:
kubectl apply -f redis.yaml
Odczyta ono parametry z pliku redis.yaml i prześle je do klastra.
Oto polecenie umożliwiające dostęp do wszystkich podów, jeśli takie istnieją:
kubectl get pods
NAME READY STATUS RESTARTS AGE
redis 0/1 ContainerCreating 0 7s
Wykonaj ponownie to polecenie po kilku sekundach i zobacz różnicę:
kubectl get pods
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 81s
W tym kroku utworzono nowy pod na klastrze dockerspace i został on uruchomiony.
W następnym kroku wejdziesz do kontenera i zaczniesz wydawać polecenia, tak jak w każdym innym środowisku Linux.
Krok 4 - Wykonywanie poleceń bash w kontenerze
W tym kroku w kontenerze uruchomiona zostanie powłoka bash, co w systemie Linux jest równoznaczne z uruchomieniem systemu operacyjnego:
kubectl exec -it redis -- /bin/bash
W odpowiedzi zostaje wyświetlona lista:
root@redis:/data# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 50G 1.4G 49G 3% /
tmpfs 64M 0 64M 0% /dev
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/vdb 50G 1.4G 49G 3% /data
/dev/vda4 32G 4.6G 27G 15% /etc/hosts
shm 64M 0 64M 0% /dev/shm
tmpfs 3.9G 16K 3.9G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 3.9G 0 3.9G 0% /proc/acpi
tmpfs 3.9G 0 3.9G 0% /proc/scsi
tmpfs 3.9G 0 3.9G 0% /sys/firmware
W terminalu będzie to wyglądać tak:
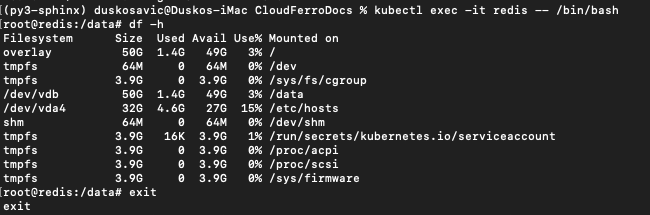
Zauważ, że monit zmienił się na
root@redis:/data#
Oznacza to, że teraz wydajesz polecenia wewnątrz samego kontenera. Pod działa jako Fedora 33 i można użyć polecenia df, aby zobaczyć woluminy i ich rozmiary. Polecenie
df -h
wyświetla rozmiary plików i katalogów w sposób czytelny dla człowieka (zwykłe znaczenie parametru -h to Help, podczas gdy tutaj jest to skrót od Human).
W tym kroku aktywowano system operacyjny kontenera.
Krok 5 - Zapisywanie pliku w pamięci trwałej
W tym kroku przetestujesz trwałość plików w pamięci trwałej. Najpierw:
zapisz plik w katalogu /data/redis, a następnie
zatrzymaj proces kontenera,
ponownie wejść do poda,
znajdziesz tam nienaruszony plik.
Zauważ, że dev/vdb ma w powyższym zestawieniu rozmiar 50 GB. Dołącz go z kolumną Attached To do listy Volumes => Volumes:

Jest on powiązany z instancją:

Ta instancja jest wstrzykiwana do kontenera i jako niezależna instancja działa jako trwały magazyn dla poda.
Utwórz plik w kontenerze redis:
cd /data/redis/
echo Hello > test-file
Zainstaluj oprogramowanie, aby zobaczyć numer PID procesu Redis w kontenerze:
apt-get update
apt-get install procps
ps aux
Uruchomione procesy są następujące:

Weź numer PID dla procesu Redis (tutaj jest to 1) i zakończ go za pomocą polecenia
kill 1
Spowoduje to najpierw zakończenie pracy kontenera, a następnie zamknięcie jego wiersza poleceń.
W tym kroku utworzono plik i zakończono proces kontenera zawierającego plik. Umożlwia to przetestowanie, czy pliki przetrwają awarię kontenera.
Krok 6 - Sprawdzenie pliku zapisanego w poprzednim kroku
W tym kroku dowiesz się, czy plik test-file nadal istnieje.
Wejdź ponownie do poda, aktywuj jego powłokę bash i sprawdź, czy plik przetrwał:
kubectl exec -it redis -- /bin/bash
cd redis
ls
test-file
Istotnie, plik test-file wciąż tam jest. W trwałej pamięci masowa dla poda znajduj się na ścieżce /data/redis:

W tym kroku po ponownym wejściu do poda okazało się, że plik zachował się nienaruszony. Było to oczekiwane, ponieważ woluminy typu emptyDir przetrwają awarie kontenera, dopóki istnieje pod.
Co można zrobić dalej?
emptyDir przetrwa awarie kontenera, ale zniknie, gdy pod przestanie istnieć. Inne typy woluminów mogą lepiej przetrwać utratę podów. Na przykład:
awsElasticBlockStore spowoduje odmontowanie woluminu, gdy pod zniknie. Odmontowany i nieuszkodzony wolumin zachowa zawarte w nim dane. Ten typ woluminu może zawierać wstępnie zapisane dane i może je współdzielić między podami.
cephfs też może mieć wstępnie uzupełnione dane i udostępniać je miedzy podami. Dodatkowo może być montowany o kilku użytkowników naraz.
Mogą również obowiązywać inne ograniczenia. Na przykład niektóre z tych typów woluminów będą wymagały najpierw aktywacji własnych serwerów albo wszystkie węzły, na których działają pody, muszą być tego samego typu itd. Warunek wstępny nr 6 zawiera listę wszystkich typów wolumenów dla klastrów Kubernetes, więc warto go przestudiować i zastosować do własnych aplikacji Kubernetes.