Instalowanie i uruchamianie przepływów pracy Argo na platformie NSIS Cloud Magnum Kubernetes
Argo Workflows umożliwia uruchamianie złożonych przepływów zadań na Kubernetes. Narzędzie może:
zapewniać niestandardową logikę zarządzania zależnościami między zadaniami,
zarządzać sytuacjami, w których niektóre etapy przepływu pracy kończą się niepowodzeniem,
uruchamiać równoległa zadania przetwarzania danych lub zadania uczenia maszynowego,
uruchamiać pipeline CI/CD,
tworzyć przepływy pracy za pomocą skierowanych grafów acyklicznych (DAG) itp.
Argo stosuje natywne dla kontenerów podejście zorientowane na mikrousługi, w którym każdy krok przepływu pracy działa jako kontener.
Co zostanie omówione?
Uwierzytelnianie w klastrze
Zastosowanie wstępnej konfiguracji do PodSecurityPolicy.
Instalacja Argo Workflows w klastrze
Uruchamianie przepływów pracy Argo z chmury
Uruchamianie przepływów pracy Argo lokalnie
Uruchomienie przykładowego przepływu pracy z dwoma zadaniami
Wymagania wstępne
- Nr 1 Konto
Jest wymagane konto hostingowe NSIS z dostępem do interfejsu Horizon: https://horizon.cloudferro.com.
- Nr 2 kubectl wskazujący na klaster Kubernetes
Jeśli tworzysz nowy klaster, na potrzeby tego artykułu nazwij go argo-cluster. Zobacz atrykuł Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu przy użyciu Kubectl na NSIS OpenStack Magnum?.
Uwierzytelnianie w klastrze
Uwierzytelnijmy się w argo-cluster. Uruchom z komputera lokalnego następujące polecenie, aby utworzyć plik konfiguracyjny w bieżącym katalogu roboczym:
openstack coe cluster config argo-cluster
Spowoduje to wyświetlenie polecenia ustawiającego zmienną środowiskową KUBECONFIG wskazującą lokalizację klastra, na przykład:.
export KUBECONFIG=/home/eouser/config
Uruchom to polecenie.
Zastosowanie wstępnej konfiguracji
OpenStack Magnum domyślnie stosuje pewne ograniczenia w zasadach bezpieczeństwa dla podów działających w klastrze zgodnie z praktyką „najmniejszych uprawnień”. Argo Workflows będzie wymagać dodatkowych uprawnień, aby działać poprawnie.
Najpierw utwórz dedykowaną przestrzeń nazw dla artefaktów Argo Workflows:
kubectl create namespace argo
Następnym krokiem jest utworzenie RoleBinding, który doda rolę klastra magnum:podsecuritypolicy:privileged. Utwórz plik argo-rolebinding.yaml z następującą zawartością:
argo-rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: argo-rolebinding
namespace: argo
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: system:serviceaccounts
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: magnum:podsecuritypolicy:privileged
i zastosuj zmiany za pomocą polecenia:
kubectl apply -f argo-rolebinding.yaml
Instalacja Argo Workflows
Aby wdrożyć Argo na klastrze, uruchom następujące polecenie:
kubectl apply -n argo -f https://github.com/argoproj/argo-workflows/releases/download/v3.4.4/install.yaml
Dostępny jest również interfejs Argo CLI do uruchamiania zadań z wiersza poleceń. Jego instalacja wykracza poza zakres tego artykułu.
Uruchamianie przepływów pracy Argo z chmury
Zwykle konieczne jest uwierzytelnienie na serwerze przez logowania do interfejsu użytkownika. Tutaj zamierzamy przełączyć tryb uwierzytelniania, stosując przedstawioną poniżej poprawkę do wdrożenia (w środowiskach produkcyjnych może być konieczne włączenie odpowiedniego mechanizmu uwierzytelniania). Wykonaj następujące polecenie:
kubectl patch deployment \
argo-server \
--namespace argo \
--type='json' \
-p='[{"op": "replace", "path": "/spec/template/spec/containers/0/args", "value": [
"server",
"--auth-mode=server"
]}]'
Usługa Argo domyślnie udostępniana jest jako usługa Kubernetes typu ClusterIp, co można zweryfikować, wpisując poniższe polecenie:
kubectl get services -n argo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-server ClusterIP 10.254.248.67 <none> 2746:31294/TCP 1d
Aby udostępnić tę usługę w Internecie, należy przekonwertować typ ClusterIP na LoadBalancer, modyfikując usługę następującym poleceniem:
kubectl -n argo patch service argo-server -p '{"spec": {"type": "LoadBalancer"}}'
Po kilku minutach w chmurze zostanie wygenerowany LoadBalancer, a zewnętrzny adres IP zostanie wypełniony:
kubectl get services -n argo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
argo-server LoadBalancer 10.254.248.67 46.60.17.133 2746:31294/TCP 1d
W naszym przypadku adres IP to 46.60.17.133.
Argo jest domyślnie obsługiwany przez HTTPS z samopodpisanym certyfikatem, na porcie 2746. Tak więc, wpisując https://<your-service-external-ip>:2746 powinien być możliwy dostęp do usługi:
Uruchomienie przykładowego przepływu pracy z dwoma zadaniami
Aby uruchomić przykładowy przepływ pracy, należy najpierw zamknąć początkowe wyskakujące okienka w interfejsie użytkownika. Następnie przejdź do ikony „Workflows” w lewym górnym rogu i kliknij ją, po czym może być konieczne naciśnięcie przycisku „Continue” w kolejnym okienku.
Następnym krokiem jest kliknięcie przycisku „Submit New Workflow” w lewej górnej części ekranu, co spowoduje wyświetlenie ekranu podobnego do poniższego:
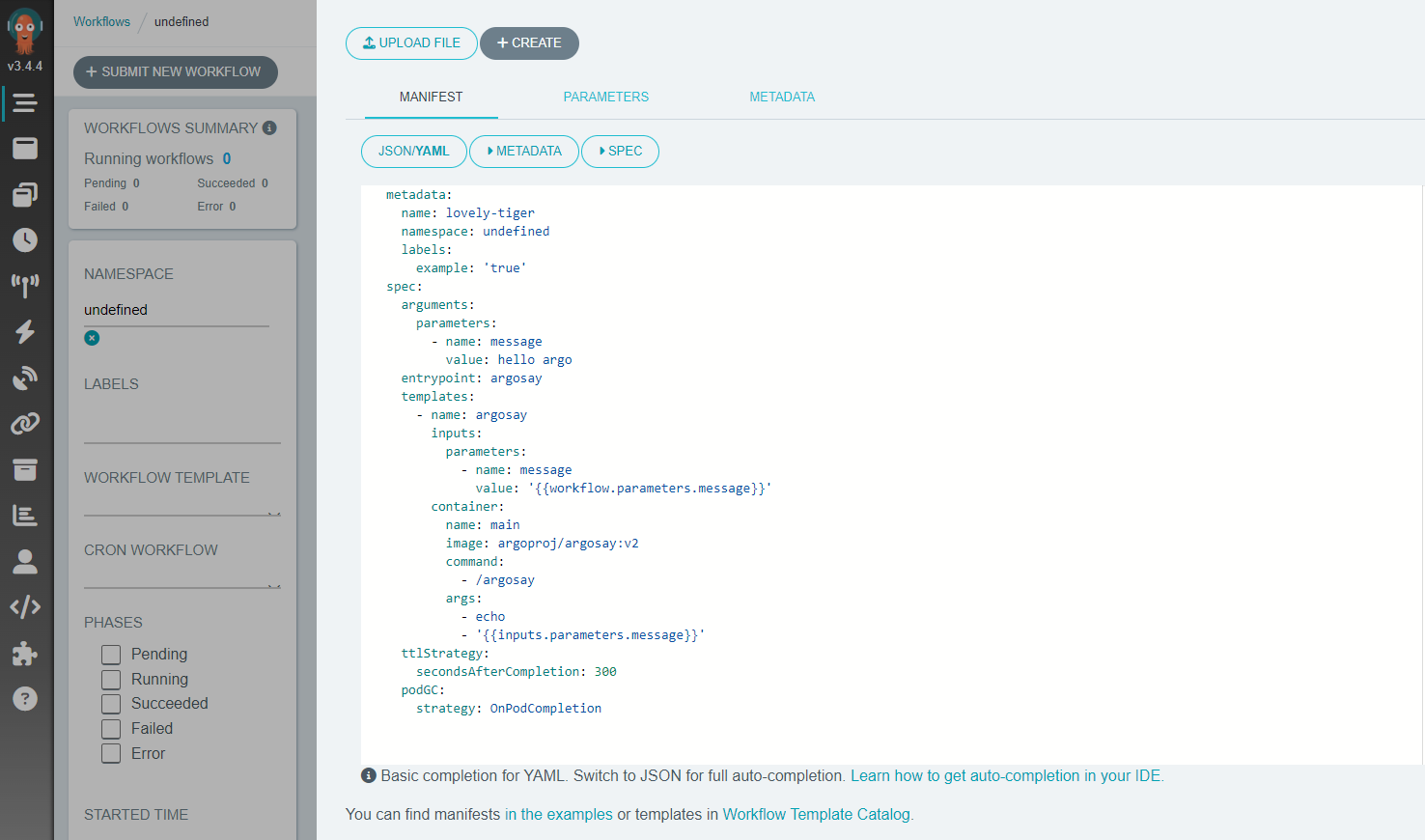
Chociaż na początek można uruchomić przepływ pracy dostarczony przez Argo, podajemy tutaj alternatywny przykład minimalny. Aby go uruchomić, należy utworzyć plik, który możemy nazwać argo-article.yaml i skopiować zamiast przykładowego manifestu YAML:
argo-article.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-
namespace: argo
spec:
entrypoint: my-workflow
serviceAccountName: argo
templates:
- name: my-workflow
dag:
tasks:
- name: downloader
template: downloader-tmpl
- name: processor
template: processor-tmpl
dependencies: [downloader]
- name: downloader-tmpl
script:
image: python:alpine3.6
command: [python]
source: |
print("Files downloaded")
- name: processor-tmpl
script:
image: python:alpine3.6
command: [python]
source: |
print("Files processed")
Ten przykład symuluje przepływ pracy z 2 zadaniami. Najpierw uruchamiane jest zadanie pobierania, a po jego zakończeniu swoją część. wykonuje zadanie przetwarzania.Kilka najważniejszych informacji na temat tej definicji przepływu pracy:
Oba zadania działają jako kontenery. Tak więc dla każdego zadania kontener python:alpine3.6 jest najpierw pobierany z rejestru DockerHub. Następnie ten kontener wykonuje prostą czynność polegającą na wyświetleniu tekstu. W przepływie pracy w środowisku produkcyjnym, zamiast używać skryptu, kod z logiką zostanie pobrany z rejestru kontenerów jako niestandardowy obraz Docker.
Kolejność wykonywania skryptu jest tutaj definiowana przy użyciu DAG (Directed Acyclic Graph). Pozwala to na określenie zależności zadań w sekcji zależności. W naszym przypadku zależność jest umieszczona na procesorze, więc rozpocznie się dopiero po zakończeniu pracy downloadera. Gdybyśmy pominęli zależności dla processora, działałby on równolegle z downloaderem.
Każde zadanie w tej sekwencji jest uruchamiane jako pod Kubernetes. Po wykonaniu zadania pod kończy działanie, co zwalnia zasoby w klastrze.
Możesz uruchomić ten przykład, klikając przycisk „+Create”. Po zakończeniu przepływu pracy powinien zostać wyświetlony wynik jak poniżej:

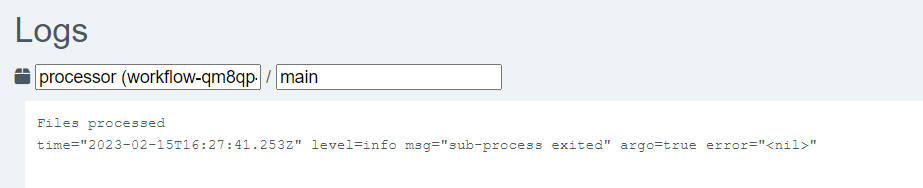
Ponadto po kliknięciu każdego kroku po prawej stronie ekranu wyświetlanych jest więcej informacji. Na przykład, klikając na krok Procesor, możemy zobaczyć logi w prawej dolnej części ekranu.
Wyniki pokazują, że rzeczywiście w kontenerze został wyświetlony komunikat „Files processed”:
Co można zrobić dalej?
W środowisku produkcyjnym należy rozważyć alternatywny mechanizm uwierzytelniania i zastąpienie samopodpisanych certyfikatów HTTPS certyfikatami wygenerowanymi przez urząd certyfikacji.