Jak utworzyć klaster Kubernetes przy użyciu Terraform na NSIS
W tym artykule pokażemy użycie Terraform do wdrożenia klastra OpenStack Magnum Kubernetes w chmurze NSIS.
Wymagania wstępne
Nr 1 Konto hostingowe
Jest wymagane aktywne konto NSIS https://NSIS-Cloudcloud-innovation.cloudferro.com/login.
Nr 2 Aktywna sesja CLI z OpenStackClient dla Linux
Wymagany jest zainstalowany OpenStack CLI i odpowiednie środowisko wirtualne Python. Wskazówki można znaleźć w artykule
Jak zainstalować OpenStackClient dla systemu Linux na NSIS
Przedstawia on, jak zainstalować środowisko Python, utworzyć i aktywować środowisko wirtualne, a następnie połączyć się z chmurą, pobierając i aktywując odpowiedni plik RC z chmury NSIS.
Nr 3 Połączenie z chmurą za pomocą pliku RC
Kolejny artykuł, Jak aktywować dostęp OpenStack CLI do chmury NSIS przy użyciu uwierzytelniania dwuskładnikowego , dotyczy łączenia się z chmurą i obejmuje jedną z procedur uwierzytelniania jedno- lub dwuskładnikowego, które są włączone na koncie. Artykuł omawie również wszystkie główne platformy: Linux, MacOS i Windows.
Będziesz używać zarówno wirtualnego środowiska Python, jak i pobranego pliku RC po zainstalowaniu Terraform.
Nr 4 Znajomość tworzenia klastrów Kubernetes
Znajomość tworzenia klastrów Kubernetes w standardowy sposób, na przykład za pomocą Horizon lub OpenStack CLI:
Jak utworzyć klaster Kubernetes przy użyciu NSIS OpenStack Magnum
Jak korzystać z interfejsu wiersza poleceń dla klastrów Kubernetes w NSIS OpenStack Magnum
Nr 5 Działający Terraform
Zainstaluj Terraform lokalnie lub na maszynie wirtualnej w chmurze. Wskazówki dotyczące instalacji wraz z dalszymi informacjami można znaleźć w artykule:
Generowanie i autoryzacja Terraform przy użyciu użytkownika Keycloak na NSIS Cloud
Po zakończeniu pracy z tym artykułem będziesz mieć dostęp do chmury za pośrednictwem aktywnego polecenia openstack. Ponadto, specjalne zmienne środowiskowe (env) (OS_USERNAME, OS_PASSWORD, OS_AUTH_URL i inne) zostaną skonfigurowane tak, by różne programy mogły z nich korzystać – głównym celem jest tutaj Terraform .
Definiowanie dostawcy dla Terraform
Terraform używa pojęcia provider, które reprezentuje konkretne środowisko chmury i obejmuje uwierzytelnianie. Chmury NSIS są budowane zgodnie z technologią OpenStack, a OpenStack jest jednym ze standardowych typów dostawców dla Terraform.
Musimy:
poinstruować Terraform, aby używał OpenStack jako typu dostawcy
podać dane uwierzytelniające, które będą wskazywać na nasz projekt i użytkownika w chmurze.
Zakładając, że jest spełnione Wymaganie wstępne Nr. 2 (pobranie i skopiowanie pliku RC), kilka zmiennych środowiskowych związanych z OpenStack zostanie wypełnionych w twoim systemie lokalnym. Zmienne wskazujące na środowisko OpenStack zaczynają się od OS, na przykład OS_USERNAME, OS_PASSWORD, OS_AUTH_URL. Kiedy zdefiniujemy OpenStack jako typ dostawcy Terraform, Terraform będzie wiedział, aby automatycznie używać tych zmiennych env do uwierzytelniania.
Zdefiniujmy teraz dostawcę Terraform, tworząc plik provider.tf o następującej zawartości:
provider.tf
# Define providers
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "~> 1.35.0"
}
}
}
# Configure the OpenStack Provider
provider "openstack" {
auth_url = "https://keystone.cloudferro.com:5000/v3"
# the rest of configuration parameters are taken from environment variables once RC file is correctly sourced
}
Opcja auth_url jest jedyną opcją konfiguracji, którą należy podać w pliku konfiguracyjnym, mimo że jest ona również dostępna w zmiennych środowiskowych.
Posiadanie tej specyfikacji dostawcy umożliwia utworzenie klastra w kolejnych krokach, ale może być ona również ponownie wykorzystana do tworzenia innych zasobów w środowisku OpenStack, na przykład maszyn wirtualnych, woluminów i wielu innych.
Definiowanie zasobu klastra w Terraform
Drugim krokiem jest zdefiniowanie dokładnej specyfikacji zasobu, który chcemy utworzyć za pomocą Terraform. W naszym przypadku chcemy utworzyć klaster OpenStack Magnum. W terminologii Terraform będzie to instancja typu zasobu openstack_containerinfra_cluster_v1. Aby kontynuować, utwórz plik cluster.tf, który zawiera specyfikację naszego klastra:
cluster.tf
# Create resource
resource "openstack_containerinfra_cluster_v1" "k8s-cluster" {
name = "k8s-cluster"
cluster_template_id = "cc4c10ae-8321-4771-91b4-519ff52967b0"
node_count = 3
master_count = 3
flavor = "eo1a.large"
master_flavor = "hmad.medium"
keypair = "klucz"
labels = {
eodata_access_enabled = true
etcd_volume_size = 0
}
merge_labels = true
}
Powyższa konfiguracja odzwierciedla klaster z kilkoma często używanymi dostosowaniami:
- cluster_template_id
odpowiada identyfikatorowi jednego z domyślnych szablonów klastrów, którym jest k8s-v1.31.10-1.0.0-cilium. Domyślne szablony i ich identyfikatory można sprawdzić w interfejsie Horizon UI w podmenu Cluster Infra -→ Container Templates.
- node_count, node_flavor, master_node_count, master_node_flavor
odpowiadają intuicyjnie liczbie i rodzajowi węzłów nadrzędnych i podrzędnych w klastrze.
- keypair
oznacza nazwę pary kluczy używanej w naszym projekcie openstack w wybranej chmurze.
- labels i merge_labels
Używamy dwóch etykiet:
- eodata_access_enabled=true
zapewnia, że sieć EODATA z szybkim dostępem do zdjęć satelitarnych jest połączona z węzłami naszego klastra,
- etcd_volume_size=0
zapewnia, że węzły główne są prawidłowo wyposażone w lokalną pamięć masową NVME.
W przypadku tej konfiguracji obowiązkowe jest również użycie parametru merge_labels=true, aby poprawnie zastosować te etykiety i uniknąć ich zastąpienia przez domyślne ustawienia szablonu.
Dostępne flavory znajdziesz za pomocą poniższego polecenia. W przykładzie używamy hmad.medium, co można zmienic wedle potrzeby. .. code:
openstack flavor list
Powyższa konfiguracja odzwierciedla klaster, w którym loadbalancer jest umieszczony przed węzłami głównymi, a flavor tego loadbalancera to HA-large. Dostosowanie tego domyślnego ustawienia, podobnie jak w przypadku innych bardziej zaawansowanych ustawień domyślnych, wymagałoby utworzenia niestandardowego szablonu Magnum, co wykracza poza zakres tego artykułu.
Zastosowanie konfiguracji i utworzenie klastra
Po zdefiniowaniu obu konfiguracji Terraform opisanych w poprzednich krokach możemy je zastosować w celu utworzenia naszego klastra.
Pierwszym krokiem jest przygotowanie obu plików provider.tf i cluster.tf w dedykowanym katalogu. Następnie przejdź do tego katalogu (cd ) i wpisz polecenie:
terraform init
To polecenie zainicjuje wdrożenie naszego klastra. Wykryje ono wszelkie formalne błędy związane z uwierzytelnianiem w OpenStack, które mogą wymagać korekty przed przejściem do następnego etapu.
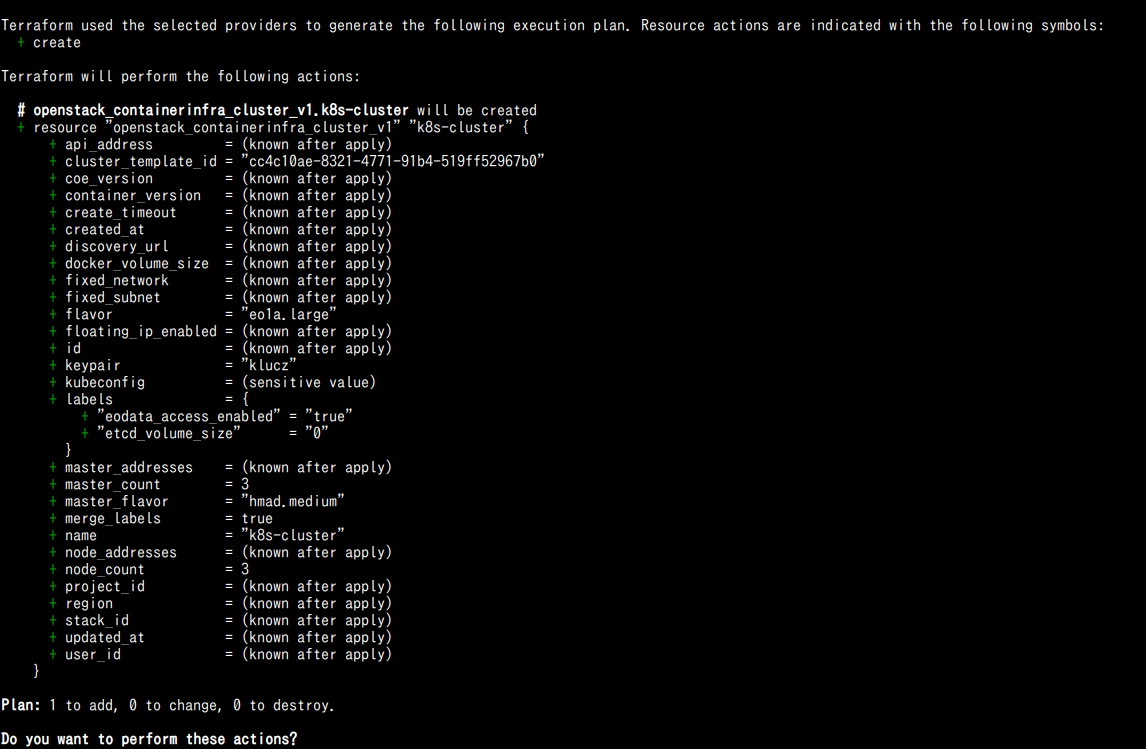
W następnym kroku Terraform zaplanuje działania, które musi wykonać, aby utworzyć zasób. Wpisz polecenie:
terraform plan
Wynik jest przedstawiony poniżej i umożliwia poprawienie wszelkich błędów logicznych w oczekiwanej konfiguracji:
Ostatnim krokiem jest zastosowanie zaplanowanych zmian. Wykonaj ten krok za pomocą polecenia:
terraform apply
Wynik tego ostatniego polecenia najpierw powtórzy plan, a następnie poprosi o wpisanie słowa yes, aby uruchomić Terraform.
Po potwierdzeniu przez wpisanie yes, akcja zostanie wdrożona, a konsola będzie aktualizować się co 10 sekund, wyświetlając komunikat „Still creating …”, aż klaster zostanie utworzony.
Ostatnie wiersze danych wyjściowych po pomyślnym skonfigurowaniu klastra powinny wyglądać podobnie do poniższych:

Co można zrobić dalej?
Terraform może być również używany do wdrażania dodatkowych aplikacji w klastrze, na przykład przy użyciu dostawcy Helm dla Terraform. Więcej informacji szczegółowych można znaleźć w dokumentacji Terraform.