Dostęp do EODATA z podów Kubernetes w NSIS Cloud przy użyciu boto3
Podczas korzystania z Kubernetes w chmurach NSIS możesz wkrótce potrzebować dostępu do repozytorium obrazów satelitarnych EODATA.
Typowym przypadkiem użycia może być na przykład przetwarzanie zadań wsadowych, w którym pody Kubernetes inicjują pobieranie obrazów EODATA w celu ich dalszego przetwarzania.
Ten artykuł wyjaśnia, w jaki sposób dostęp do EODATA jest zaimplementowany w OpenStack Magnum i jak wykorzystuje bibliotekę Pythona boto3 do uzyskiwania dostępu do EODATA z podów Kubernetes. Docker i DockerHub posłużą do konteneryzacji i wdrożenia aplikacji uzyskującej dostęp do EODATA.
Wymagania wstępne
Nr 1 Konto
Jest wymagane konto hostingowe NSIS z dostępem do interfejsu Horizon: https://horizon.cloudferro.com.
Nr 2 Klaster Kubernetes z dostępem do EODATA
Klaster Kubernetes w chmurze NSIS utworzony z opcją „EODATA access enabled”. Patrz artykuł w bazie wiedzy Jak utworzyć klaster Kubernetes przy użyciu NSIS OpenStack Magnum.
Nr 3 Znajomość kubectl
Więcej instrukcji można znaleźć w artykule Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu przy użyciu Kubectl na NSIS OpenStack Magnum?.
Nr 4 Zrozumienie, w jaki sposób biblioteka boto3 uzyskuje dostęp do EODATA
Aby dowiedzieć się, jak uzyskać dostęp do EODATA bez Kubernetes, zapoznaj się z artykułem Jak uzyskać dostęp do EODATA za pomocą boto3 na NSIS Cloud.
W szczególności artykuł Jak uzyskać poświadczenia używane do uzyskiwania dostępu do EODATA na maszynie wirtualnej w chmurze NSIS? wyjaśnia, jak uzyskać odpowiednie poświadczenia w zależności od używanej chmury.
Nr 5 Docker zainstalowany na komputerze
Zobacz artykuł Jak zainstalować i używać Dockera na Ubuntu 24.04.
Nr 6 Konto w DockerHub
Konto w serwisie DockerHub. Można korzystać z innych rejestrów obrazów, ale wykracza to poza zakres tego artykułu.
Co zamierzamy zrobić?
Przedstawić podstawowe informacje na temat korzystania z EODATA w Magnum
Przygotować obraz Docker aplikacji uzyskującej dostęp do EODATA za pomocą boto3
Utworzyć obraz Docker i przesłać go do DockerHub
Uruchomić poda Kubernetes z kontenerem Docker i zweryfikować dostęp do EODATA
Krok 1 Utworzenie klastra Kubernetes z EODATA
W chmurze NSIS każdy projekt ma domyślnie dołączoną sieć EODATA. W związku z tym podczas tworzenia maszyny wirtualnej w OpenStack istnieje opcja dodania sieci EODATA do takiej maszyny wirtualnej.
Ponieważ klaster Kubernetes zbudowany na Magnum jest tworzony z tych samych maszyn wirtualnych, można zapewnić dostęp do EODATA każdemu węzłowi roboczemu w klastrze. Użyj poleceń Container Infra → Clusters → Create Cluster, aby rozpocząć tworzenie klastra i zaznacz pole „EODATA access enabled”.
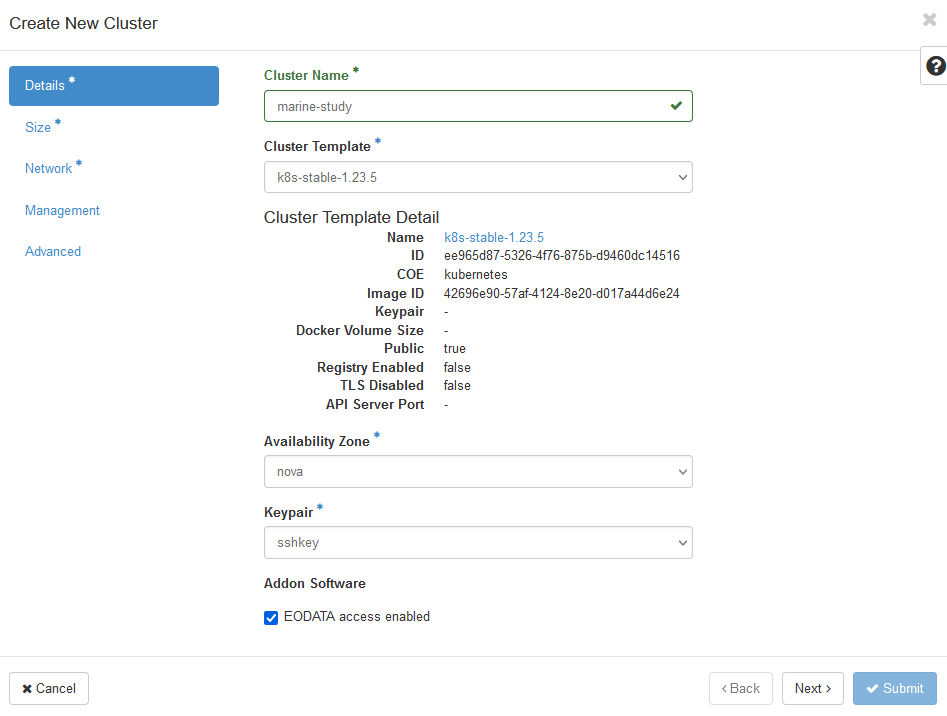
Po zakończeniu tworzenia klastra sprawdź, czy węzły zostały prawidłowo podłączone do EODATA. Przejdź do Compute → Instances i sprawdź, czy adres IP węzłów roboczych znajduje się w sieci EODATA. Na poniższej ilustracji marine-study to nazwa klastra, natomiast eodata_00341_3 będzie nazwą sieci EODATA:

Dwa węzły robocze są połączone z siecią eodata_, podczas gdy węzeł główny nie jest. Dzieje się tak, ponieważ węzły główne zarządzające klastrem i nie mają dostępu do EODATA.
Poniżej przedstawiono, jak można dostarczyć oprogramowanie do dostępu do EODATA za pomocą obrazu Docker.
Krok 2 Przygotowanie obrazu Docker aplikacji
boto3 to standardowa biblioteka środowiska Python służąca do interakcji z obiektowymi pamięciami masowymi S3. Strategicznie rzecz biorąc, budowany kontener musi zawierać następujące elementy:
zainstalowane środowisko Python i boto3
prawidłowe punkty końcowe dostępu do EODATA
poświadczenia S3 umożliwiające dostęp do tych punktów końcowych.
Za pomocą poniższych trzech plików można „dockeryzować” aplikację, czyli zbudować jej obraz Docker i wysłać go do DockerHub:
konkretny plik w języku Python z kodem aplikacji (w naszym przypadku app.py)
plik requirements.txt określający zależności dla biblioteki boto3
plik Dockerfile zawierający instrukcje dotyczące tworzenia kontenera
Plik Dockerfile będzie oparty na środowisku Python 3.8, zainstaluje boto3, a następnie uruchomi aplikację. W kodzie aplikacji pobieramy przykładowy obraz i każemy kontenerowi czekać 300 sekund. Potrzeba tylko kilku sekund, aby sprawdzić, czy obraz został pobrany poprawnie, więc pięć minut to więcej niż wystarczające. Utwórz następujące trzy pliki i umieść je w tym samym katalogu:
app.py
import boto3 import time access_key='anystring' secret_key='anystring' key='Landsat-5/TM/L1T/2011/11/11/LS05_RKSE_TM__GTC_1P_20111111T093819_20111111T093847_147313_0191_0025_1E1E/LS05_RKSE_TM__GTC_1P_20111111T093819_20111111T093847_147313_0191_0025_1E1E.BP.PNG' host='http://data.cloudferro.com' s3=boto3.resource('s3',aws_access_key_id=access_key, aws_secret_access_key=secret_key, endpoint_url=host,) bucket=s3.Bucket('eodata') bucket.download_file(key, '/app/image.png') time.sleep(300)
requirements.txt
boto3==1.21.41
Dockerfile
# syntax=docker/dockerfile:1
FROM python:3.8-slim-buster
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD [ "python3", "-m", "app.py"]
Krok 3 Utworzenie obrazu aplikacji i przesłanie go do DockerHub
Aby utworzyć obraz Docker i wysłać go do DockerHub, uruchom następujące polecenie z katalogu, w którym znajdują się pliki (wybierz dowolną nazwę repozytorium):
Informacja
W zależności od konfiguracji może być konieczne poprzedzenie poleceń Docker poleceniem sudo.
docker build -t <your-dockerhub-account>/<your-repository-name> .
Upewnij się, że jesteś zalogowany(-a) do DockerHub:
docker login -u <your-dockerhub-username> -p <your-dockerhub-password>
Następnie wyślij obraz do DockerHub (jeśli repozytorium nie istnieje, zostanie utworzone w DockerHub):
docker push <your-dockerhub-account>/<your-repository-name>
Możesz sprawdzić, czy obraz został przesłany, sprawdzając go w internetowym interfejsie graficznym DockerHub.
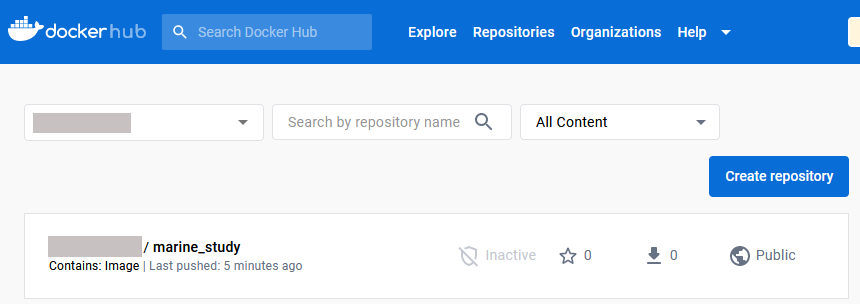
Na tej ilustracji repozytorium jest już publiczne. Jeśli jest prywatne, należy je upublicznić, klikając nazwę repozytorium, a następnie Settings -> Visibility settings.
Krok 4 Wdrożenie aplikacji na platformie Kubernetes
Obraz został utworzony i umieszczony w DockerHub, możesz teraz wdrożyć aplikację jako pod Kubernetes. Zwykle dla poda tworzy się manifest YAML, ale tutaj, dla zwięzłości, wdraża się go za pomocą wiersza poleceń. Aby to zrobić, wpisz następujący fragment (utwórz dowolną nazwę poda):
kubectl run <your-pod-name> --image=<your-dockerhub-account>/<your-repository-name>
Uruchomienie powyższego polecenia powoduje wdrożenie poda, który uruchamia skonteneryzowaną aplikację Python. Ponieważ mamy 5 minut do zakończenia działania aplikacji (a tym samym również poda), możemy sprawdzić, czy obraz został pobrany za pomocą następującego polecenia:
$ kubectl exec --tty --stdin <your-pod-name> -- sh
Pozwoli to wejść do powłoki kontenera w podzie. Symbol wiersza poleceń zmieni się w podzie z $ na #. Możesz sprawdzić, czy obraz został pobrany do poda, przechodząc do katalogu /app i wyświetlając jego zawartość.

Co można zrobić dalej?
Postępując zgodnie ze wskazówkami zawartymi w tym artykule, można wdrożyć bardziej złożone scenariusze, na przykład używając wdrożeń lub zadań zamiast podów.
W przypadku scenariuszy produkcyjnych warto umieścić poświadczenia S3 w tajnym kluczu Kubernetes lub w rejestrze tajnych kluczy, takim jak HashiCorp Vault. Zobacz artykuł Instalacja HashiCorp Vault na NSIS Magnum.