Instalacja i uruchamianie Dask na klastrze Kubernetes w chmurze NSIS Cloud
Dask umożliwia skalowanie zadań obliczeniowych jako wielu procesów na jednej maszynie lub w klastrach Dask, które składają się z wielu maszyn roboczych. Dask zapewnia skalowalną alternatywę dla popularnych bibliotek w języku Python, np. Numpy, Pandas lub SciKit Learn, ale nadal wykorzystuje kompaktowe i bardzo podobne API.
Po przesłaniu zadania obliczeniowego harmonogram Dask dzieli je na mniejsze zadania, które mogą być wykonywane równolegle na węzłach lub w procesach roboczych.
Pracując z tym artykułem zainstalujesz klaster Dask na Kubernetes i uruchomisz węzły robocze Dask jako pody Kubernetes. Podczas instalacji uzyskasz dostęp do instancji Jupyter, w której możesz uruchomić przykładowy kod.
Co zostanie omówione?
Instalacja Dask na Kubernetes
Dostęp do pulpitu nawigacyjnego Jupyter i Dask Scheduler
Uruchomienie przykładowego zadania obliczeniowego
Konfiguracja klastra Dask na platformie Kubernetes z poziomu środowiska Python
Diagnozowanie i usuwanie błędów
Wymagania wstępne
Nr 1 Hosting
Wymagane jest konto hostingowe NSIS z interfejsem Horizon https://horizon.cloudferro.com.
Nr 2 Klaster Kubernetes w chmurze CloudFerro
Aby utworzyć klaster Kubernetes w chmurze, zapoznaj się z przewodnikiem Jak utworzyć klaster Kubernetes przy użyciu NSIS OpenStack Magnum.
Nr 3 Dostęp do linii poleceń kubectl
Instrukcje dotyczące aktywacji kubectl znajdują się w artykule Jak uzyskać dostęp do klastra Kubernetes po wdrożeniu przy użyciu Kubectl na NSIS OpenStack Magnum?.
Nr 4 Znajomość Helm
Aby uzyskać więcej informacji na temat korzystania z Helm i instalowania aplikacji z Helm na Kubernetes, zapoznaj się z artykułem /kubernetes/Deploying-Helm-Charts-on-Magnum-Kubernetes-Clusters-on-NSIS-Cloud
Nr 5 Środowisko Python3 dostępne na komputerze
Python3 preinstalowany na komputerze.
Nr 6 Podstawowa znajomość bibliotek naukowych Jupyter i Python
Jako przykładu użyjemy Pandas.
Krok 1 Instalacja Dask na Kubernetes
Aby zainstalować Dask jako chart Helm, najpierw pobierz repozytorium Dask Helm:
helm repo add dask https://helm.dask.org/
Zamiast instalować chart Helm od zera, dla wygody dostosujmy konfigurację . Aby wyświetlić wszystkie możliwe konfiguracje i ich wartości domyślne, uruchom polecenie:
helm show dask/dask
Przygotuj plik dask-values.yaml, aby zastąpić niektóre wartości domyślne:
dask-values.yaml
scheduler:
serviceType: LoadBalancer
jupyter:
serviceType: LoadBalancer
worker:
replicas: 4
Zmienia to domyślny typ usługi dla Jupyter i Scheduler na LoadBalancer, dzięki czemu są one publicznie dostępne. Ponadto domyślna liczba węzłów roboczych Dask wynosi 3, ale teraz została zmieniona na 4. Każdemu podowi roboczemu Dask zostanie przydzielone 3GB pamięci RAM i 1 procesor.
Aby wdrożyć wykres Helm, utwórz przestrzeń nazw dask i zainstaluj go w niej:
helm install dask dask/dask -n dask --create-namespace -f dask-values.yaml
Krok 2 Uzyskanie dostępu do pulpitu nawigacyjnego Jupyter i Dask Scheduler
Po zakończeniu instalacji można uzyskać dostęp do usług Dask:
kubectl get services -n dask
Istnieją dwie usługi, dla Jupyter i Dask Scheduler dashboard. Wypełnienie zewnętrznych adresów IP zajmie kilka minut:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dask-jupyter LoadBalancer 10.254.230.230 46.60.20.14 80:32437/TCP 6m49s
dask-scheduler LoadBalancer 10.254.41.250 46.60.23.190 8786:31707/TCP,80:31668/TCP 6m49s
Możemy wkleić zewnętrzny adres IP do przeglądarki, aby wyświetlić usługi. Aby uzyskać dostęp do Jupytera, należy najpierw przejść przez ekran logowania, domyślne hasło to dask. Następnie można wyświetlić instancję Jupyter:
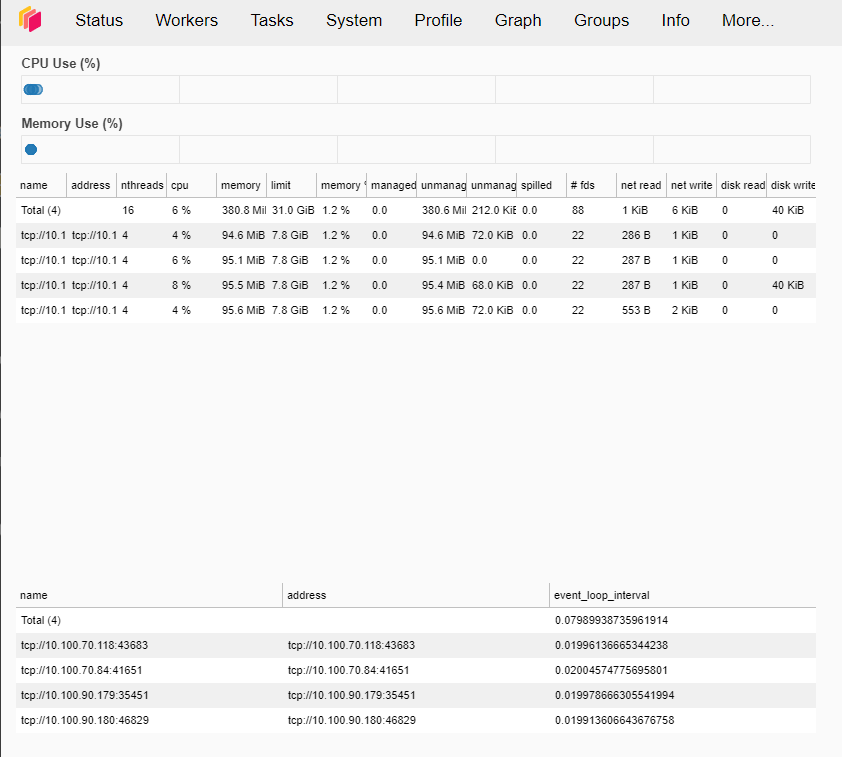
Podobnie w przypadku pulpitu nawigacyjnego Scheduler Dashboard, wklej adres floating IP do przeglądarki, aby go wyświetlić. Jeśli następnie klikniesz kartę „Workers” powyżej, zobaczysz, że w naszym klastrze Dask uruchomione są 4 wężły robocze:
Krok 3 Uruchomienie przykładowego zadania obliczeniowego
Zainstalowana instancja Jupyter zawiera już zainstalowany Dask i inne przydatne biblioteki Python. Aby uruchomić przykładowe zadanie, najpierw aktywuj notatnik, klikając ikonę NoteBook → Python3(ipykernel) po prawej stronie ekranu przeglądarki instancji Jupyter.
Przykładowe zadanie wykonuje obliczenia na tabeli (ramce danych) zawierającej 100tys. wierszy i tylko jedną kolumnę. Każdy rekord zostanie wypełniony losową liczbą całkowitą z zakresu od 1 do 100000, a zadaniem jest obliczenie sumy wszystkich rekordów.
Kod uruchomi ten sam przykład dla Pandas (pojedynczy proces) i Dask (z przetwarzaniem równoległym w naszym klastrze) i będziemy mogli sprawdzić wyniki.
Skopiuj poniższy kod i wklej go do komórki w notatniku Jupyter:
import dask.dataframe as dd
import pandas as pd
import numpy as np
import time
data = {'A': np.random.randint(1, 100_000_000, 100_000_000)}
df_pandas = pd.DataFrame(data)
df_dask = dd.from_pandas(df_pandas, npartitions=4)
# Pandas
start_time_pandas = time.time()
result_pandas = df_pandas['A'].sum()
end_time_pandas = time.time()
print(f"Result Pandas: {result_pandas}")
print(f"Computation time Pandas: {end_time_pandas - start_time_pandas:.2f} seconds.")
# Dask
start_time_dask = time.time()
result_dask = df_dask['A'].sum().compute()
end_time_dask = time.time()
print(f"Result Dask: {result_dask}")
print(f"Computation time Dask: {end_time_dask - start_time_dask:.2f} seconds.")
Naciśnij przycisk odtwarzania lub użyj opcji Run z menu głównego, aby wykonać kod. Po kilku sekundach wynik pojawi się pod komórką z kodem.
Poniżej przedstawiono niektóre z wyników, które możemy zaobserwować dla tego przykładu:
Result Pandas: 4999822570722943
Computation time Pandas: 0.15 seconds.
Result Dask: 4999822570722943
Computation time Dask: 0.07 seconds.
Należy zauważyć, że wyniki te nie są deterministyczne i proste Pandas mogą również osiągać lepsze wyniki w poszczególnych przypadkach. Należy również wziąć pod uwagę narzut związany z dystrybucją i zbieraniem wyników od węzłów roboczych Dask. Dalsze dostrajanie wydajności Dask wykracza poza zakres tego artykułu.
Krok 4 Konfiguracja klastra Dask na platformie Kubernetes z poziomu środowiska Python
Do zarządzania klastrem Dask na Kubernetes możemy użyć dedykowanej biblioteki Pythona dask-kubernetes. Za pomocą tej biblioteki można rekonfigurować niektóre parametry klastra Dask.
Jednym ze sposobów na uruchomienie dask-kubernetes byłaby instancja Jupytera, ale wtedy musielibyśmy podać odniesienie do kubeconfig naszego klastra. Zamiast tego instalujemy dask-kubernetes w środowisku lokalnym za pomocą następującego polecenia:
pip install dask-kubernetes
Gdy to zrobimy, będziemy mogli zarządzać klastrem Dask z poziomu środowiska Python. Jako przykład, przeskalujmy go do 5 węzłów Dask. Użyj nano, aby utworzyć plik scale-cluster.py:
nano scale-cluster.py
Następnie wstaw następujące polecenia:
scale-cluster.py
from dask_kubernetes import HelmCluster
cluster = HelmCluster(release_name="dask", namespace="dask")
cluster.scale(5)
Zastosuj zmiany za pomocą polecenia:
python3 scale-cluster.py
Za polecenia polecenia
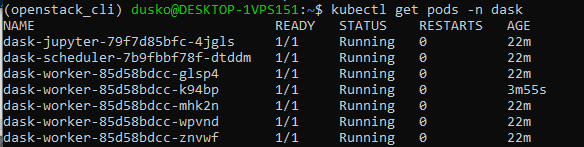
kubectl get pods -n dask
można sprawdzić, że liczba węzłów roboczych wynosi teraz 5:
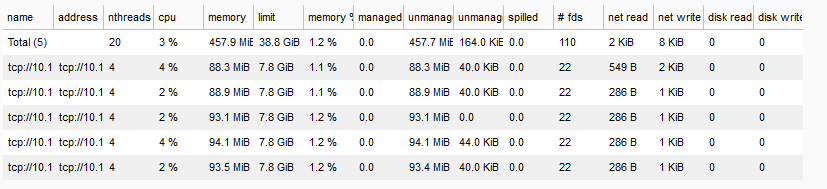
Możesz też sprawdzić aktualną liczbę węzłów roboczych w pulpicie nawigacyjnym Dask Scheduler (odśwież ekran):
Należy pamiętać, że funkcje dask-kubernetes powinny być dostępne bezpośrednio przy użyciu tylko API Kubernetes, wybór zależy od osobistych preferencji.
Diagnozowanie i usuwanie błędów
Podczas uruchamiania polecenia
python3 scale-cluster.py
w WSL w wersji1 mogą pojawić się komunikaty o błędach, takie jak te:

Kod będzie działał poprawnie, czyli zwiększy liczbę węzłów roboczych do 5, zgodnie z wymaganiami. Błąd nie powinien pojawiać się na WSL w wersji 2 i innych dystrybucjach Ubuntu.